F4 devel
F4 home
||
|
[zurück] [anfang] [mail] |
[en: [L4] [F4] [L4 glos] [F4 glos] ] | [de: [L4] [F4] [F4 Glos] ] | FORTH e.V. | (23) ca 40 Seiten A4, Text, 110 Zch/Zeile+'upn.jpg' |
|
F4 devel |
F4 home |
...soll anhand einer Reihe von Versuchen und Beispielen die grundlegenden Konzepte von Forth als Computersprache
und Entwicklungsumgebung vorstellen, die jede Form der Datenverarbeitung in besonders effizienter und vor allem
zuverlässiger Form auf sehr einfache Weise unterstützt. Er beschreibt möglichst allgemeingültig
ein Basis-System auf Grundlage der Standards des us-ANSI, wie es u.a. mit der lib4th-Sammlung
"L4", in erweiterter Form vorliegt, und enthält, soweit wesentliche Unterschiede zu verzeichnen sind,
auch entsprechende Hinweise auf den älteren fig-Forth-Standard (1.0) mit Beispielen anhand des
F4 desselben Autors.
Zu beiden gibt es erschöpfende weiterführende Informationen in Gestalt
erklärender Texte ("Glossare" - F4, L4)
wie auch der ausführlich kommentierten Assembler-Quellen für
F4 oder L4 (sowohl mit ANS-Forth-
als auch fig-Forth-Modus). Derartige Details bleiben hier ebenso außer acht,
wie etwa die Eigenschaften von Forth als eigenständigen und kompakten
Betriebssystems. Forth ist damit auch für Startsysteme
größerer Rechner oder für Contoller ("embedded systems",
Gerätesteuerung) praedestiniert, es ist aber keineswegs auf dergleichen
beschränkt!
ANS-Forth ist ein Standard-Forth-System, dessen Beschreibung im
DPANS94-Dokument frei verfügbar ist; auch ein
gleichlautender ISO-Standard existiert (ISO/IEC 15145). 'ANS' bezeichnet (in der
üblichen Verblendung) das nationale Normen-Institut der U.S.A, welches mir ansich
herzlich egal ist, nur steht mir eben genau nur jenes Dokument zur Verfügung. Die ISO
kommt mit Freudenhauspreisen einher (230 CHF), aufgrund derer ich garnicht erst ernsthaft
gesucht habe; im übrigen hat sie ausdrücklich das us-ANSI als hierfür
federführend benannt, sodaß Bemühungen um die ISO-Unterlagen ohnehin nur,
wenn ein System explizit 'ISO/IEC-Forth' benannt werden soll, sinnvoll sind. Das mag etwa
unter kommerziellen Gesichtspunkten in gewissen Fällen notwendig sein, für diese
Beschreibung ist es belanglos.
Ausprobieren der Beispiele und Variieren derselben sei ausdrücklich empfohlen; der eigenen Neugier folgendes Vorgehen kann den Effekt nur verbessern. Partien zur Eingabe im Forth, z.B. nach Aufruf des Beispielprogramms "4", erscheinen großgeschrieben und eingerückt, Beispiele im Text zwischen "{...}" geschweiften Klammern. Sie können in beliebiger Schreibweise (L4, F4) eingegeben werden, für ANS-Forth ist die Erkennbarkeit aller Worte in Großbuchstaben garantiert. Wo zugunsten der L4 oder für F4 vom ANS-Forth Standard abzuweichen war, findet sich ein entsprechender Hinweis.
Die Voraussetzungen sind gering:
Bei unvoreingenommenem, eigenständigem und geradlinigem Denken sollte es mit Forth keine Schwierigkeiten
geben. Ein wenig grob: Forth fordert 'Selberdenken', simpel 'Mitdenken' genügt nicht, gelehriges Nachplappern
nützt garnichts, folgsame Opportunisten werden im allgemeinen schnell scheitern und der Glaube an irgendwelche
'Gurus' führt kaum weiter - was insgesamt ein Grund sein mag, weshalb sich hauptberufliches Lehrpersonal und
die (leider oft nur allzu) durchschnittliche Masse beruflich Vorgesetzter gemeinhin mit Forth so schwer tun.
Darüberhinaus aber sind weder tiefere Kenntnis anderer Programmiersprachen, noch die geringste Erfahrung
etwa in der Assemblerprogrammierung oder mit sonstigen Dingen, die an's "Eingemachte" gehen, erforderlich.
Am Rande, Forth war für mich die erste ernsthaft benutzte Programmiersprache. Dank seiner Flexibilität
und grundlegenden Einfachheit hat es mir den Zugang zu Computern ungemein erleichtert. Aus dieser Erfahrung mein
Rat, sich von gegenteiligem, eher neurotischem Gerede nicht entmutigen zu lassen.
Um ein paar Gerüchte zurechtzurücken:
Wer die angedeuteten Schwachpunkte liebgewonnen hat, etwa weil sich bereits mit deren auch nur teilweiser Bewältigung so hübsch renommieren läßt, sollte also besser bei "C" oder "C++" oder Java oder sonstwas bleiben. Forth erwirbt sein Verdienst eher durch Leistung, und im Stillen.
Die Syntax von Forth ist außerordentlich einfach: Die "Sprache" ist eine Folge durch Leerzeichen
getrennter "Worte", die der Reihe nach ausgeführt werden, auch Zahlen sind in diesem Sinne "Worte".
Als Leerzeichen gelten das Leerfeld <blank>, ein Tabulatorschritt <tab> und das Zeilenende <eol>,
bei der Isolierung einzelner "Worte" werden gewöhnlich auch die anderen Steuerzeichen im Codebereich
0..31 als Leerzeichen bewertet.
Argumente werden der Reihe nach vor dem jeweiligen Aufruf angegeben, etwa
s" Alle meine Entchen..." type
Der "äußere" Interpreter beginnt unmittelbar nach Betätigung der Eingabe-Taste
rsp ganz allgemein am Zeilenende,
den betr. Text zu verarbeiten und ihn in geeigneter Form codiert dem "inneren" Interpreter zur
Ausführung zuzuleiten. Diese grundlegende Vorgehensweise ist allen Forth-Systemen gemein.
Dargestellt wird sie dagegen ganz und gar unterschiedlich, etwa in Form schrittweise
abzuarbeitender Tabellen, die auf ausführbaren Code zeigen ('directly threaded'), oder es
zeigen die Einträge auf je eine weitere Tabelle, deren erster Posten auf ausführbaren
Code zeigt, der die Ausführungsvorschrift zur Verarbeitung der darauf folgenden Daten
enthält ('indirectly threaded') oder aber in besonders einfacher und zugleich höchst
effizienter Form direkt als Processorcode, wo der Processor selbst die Wirkung des "inneren"
Interpreters hat (das heißt dann 'native code' und 'subroutine threaded'). Das Wissen um
solche Feinheiten hat eher sekundäre Bedeutung, doch da Forth bis in die tieferen Details
hinein beeinflußbar rsp nahezu unbegrenzt erweiterbar ist, werden auch dazu gelegentlich
ein paar Notizen erscheinen.
Obiges Eingabebeispiel schreibt den Text 'Alle meine Entchen...' hin; {type} ist das Forth-Wort zur Textausgabe, es erwartet als Argumente eine Textadresse und die Anzahl auszugebender Zeichen. Man beschreibt dies im Glossar gewöhnlich in der Form
type ( adresse anzahl -- ) text ausgeben.{s"} leitet einen Text ein, der nach dem trennenden Leerzeichen beginnt und vor dem abschließenden " Anführungszeichen endet. Auch {s"} ist ein Forth-Wort. Bereits dadurch, daß die betr Worte hintereinander hingeschrieben werden, gelangen die Ausgabe-Daten des ersten in die Eingabeliste des zweiten Wortes. Die Anzahl Argumente ist nicht begrenzt, weder für Eingabe noch für Ausgabe, Forth-Worte entnehmen die in ihnen selbst definierte Anzahl Argumente der Liste so, wie sie sie brauchen, und geben die ebenfalls darin festgelegte Anzahl Datenposten dorthin zurück. Es gibt keine Unterscheidung zwischen 'Funktion' und 'Procedur'.
ARBEITE, ERWIRB. Zahl' Steuern und Stürb...Die Punkte oder andere "Sonderzeichen" in einzelnen Worten haben keine besondere Bedeutung, sie dienen einzig der optischen Klarheit. Für den Forth-Interpreter zählt nur das Leerzeichen als Wort-Trennung. Alle anderen bildlich darstellbaren Zeichen können für die Namen von Forth-Worten an beliebiger Stelle beliebig verwandt werden. Die verfügbaren Schriftzeichen sind für das ANS-Forth im Zeichensatz nach "US-ASCII" mit Code-Bereich 32 bis 126 als Minimum garantiert, d.h. die einfachen Buchstaben, Ziffern und Zeichen; was darüber hinaus greifbar ist, bleibt der Einrichtung des jeweils ausgeführten Systems überlassen. Weiter wird vorausgesetzt, daß Forth-Worte des Standards vollständig in Großbuchstaben geschrieben erkannt werden.
." #S SWAP ! @ ACCEPT . *All das sind "Worte"; auch Zeichenfolgen wie $%%-GL7OP oder 4EIER:, etc. sind ordnungsgemäße Forth-Namen. Sinnvolle Namensgebung obliegt allein dem Programmierer - er ist völlig frei darin. Es gibt allerdings gewisse Konventionen für Wortnamen und Reihenfolge der Parameter, die zwar nicht ausdrücklich vereinbart sind, aber doch im allgemeinen befolgt werden. Damit soll die Deutung von Programmtexten erleichtert werden, irgendeine Wirkung auf Compiler oder Interpreter haben diese Vereinbarungen nicht.
Das eben als "Programm"-Quelle hingeschriebene, was der Äußere Forth-Interpreter zur eigentlichen Programmerzeugung verarbeitet und an die "Compiler" weiterreicht, heißt "Eingabestrom". Dieser kann vielerlei Quellen entspringen, im allgemeinen der Tastatur, einer Datei (s.u.) oder auch einem anderen Programm.
Vorneweg sei auf einen gerade anfangs sehr leicht auftretenden Fehler hingewiesen:
Ausnahmslos alle Forth-Worte werden nur erkannt, wenn sie in Leerzeichen eingeschlossen
sind. Da z.B. auch das {."} solch ein Wort ist, schreibt man etwa den sagenhaft
originellen "Hallo, Welt!"-Satz damit {." Hallo, Welt!"}. Das erste
Leerzeichen dient nur der Trennung des Forth-Wortes, es wird nicht ausgegeben. Ebensoleicht
vergißt man evtl. auch bei zusammengesetzten Texten darin enthaltene Leerzeichen:
Das Beispiel {." Hallo," ." Welt"} schreibt ohne Zwischenraum
'Hallo,Welt', die richtige Ausgabe entsteht mit zwei Leerzeichen vor der "Welt":
{." Hallo," ." Welt"}.
"Der" Compiler als Programme erzeugendes Monsterprogramm, das alles weiß und
alles steuert, und das niemand ganz durchschaut, existiert im Forth nicht: Es übergibt alle
Aufgaben an Worte als kleinste "Aktionseinheiten", wo sie nach Möglichkeit immer dann
erledigt werden, wenn die geeignete Information unmittelbar gegeben ist. Und so sind viele Forth-Worte
zugleich auch auf ihren ureigenen Zweck spezialisierte Compiler. Je nach Situation, z.B. bestimmt
durch die "STATE"-Variable, werden sie entsprechend aktiv. Deren Gesamtheit als "Compiler" steht
damit in allen Details auch der Programmierung allgemein zur Verfügung. Die
"VARIABLE" ist z.B. so ein Mini-Compiler. Anders als
bei den vielen großen Programmiersprachen stehen Compiler und Interpreter einander so nahe,
daß ein Forth-System ohne weiteres wie eine "Shell" benutzt werden kann, wobei
Compile-Vorgänge durch "Laden" von Quelltexten ebenso, wie etwa in Gestalt direkt eingegebener
Wort-Definitionen, problemlos mit den interaktiven Aufrufen
co-existieren (Forth gilt als "incrementeller Compiler"). Diese Nähe kann so weit gehen,
daß sich Interpreter und Compiler allein durch sofortige Ausführung oder zum späteren
Aufruf Belassen des erzeugten Codes im Speicher unterscheiden (L4).
Die Begriffe "Äußerer" und "Innerer" Interpreter beziehen sich auf
den Teil, der "außen" den Programmtext empfängt und den, der später im "innern" des
erzeugten Programms dafür sorgt, daß die compilierten Worte in der vorgesehenen Reihenfolge
abgearbeitet werden. Bei L4 ist letzteres der Processor des Rechners selber, sonst gibt es dafür
ein spezielles, sehr kurzes Programmstück.
Nach diesem Ausflug in die Forth-Innereien ist es nun an der Zeit, mit den ersten Versuchen zu beginnen. "Glossar", html-Dokumentation und nicht zuletzt auch das HELP-Wort im Forth (L4/F4) mögen der weiteren Erklärung dessen dienen, was mit den betr. Worten anzufangen ist, und wie sie mit geeigneten Angaben (Daten) zu versorgen sind.
Wesentliche Grundlage der Sprache sind "Stacks" (Stapel, Kellerspeicher), die den
Forth-Worten die ggf. benötigten Parameter zuführen und im übrigen ganz
allgemein der Aufbewahrung von im Verlaufe eines Programms benötigten Daten dienen.
Stacks sind Datenstrukturen, die ohne jeden zusätzlichen Aufwand ihre Speicherbereiche
allein durch die sehr einfache Zugriffsmethodik verwalten:
Daten einheitlicher Postengröße werden quasi aufeinandergeschichtet und
nach Bedarf von oben her wieder entnommen. Die alte "Groschenbox" ist ein Beispiel
aus der wirklichen Welt, oder etwa die Tellerstapel in Selbstbedienungs-Restaurants.
Wesentliche Eigenschaft von Stacks ist die Recursions- und Interrupt-tauglichkeit der
darüber abgewickelten Datenverarbeitung, zugleich bei dem geringsten überhaupt
möglichen "Verwaltungs"-Aufwand. Diese Eigenschaften sind, auch wenn das hier weiter
keine Berücksichtigung findet, von erheblicher Bedeutung für größere
Programmkomplexe oder die Ausführung (quasi-)parallelaufender Prozesse. Sie erleichtern
deren Steuerung ungemein.
Im Forth existieren mindestens zwei solcher Stapel, der Parameter- oder Daten-Stack,
der grundsätzlich zur Übergabe von Daten aller Art zwischen einzelnen Forth-Worten
verwandt wird, im allgemeinen kurz mit "Stack" bezeichnet, sowie der Return-Stack,
welcher intern der Kontrolle des Programmablaufs dient und innerhalb eines Wortes gelegentlich
auch der Zwischenspeicherung.
Mit Hilfe einiger besonderer Worte kann die Datenanordnung auf insbes. dem Daten-Stack verändert werden. Zusammen mit dem Return-Stack sind dann sämtliche "Rangierarbeiten" möglich. Da letzterer nur für relativ komplizierte Manipulationen benötigt wird, konzentriert sich das Folgende vor allem auf den Daten-Stapel als dem "Stack".
Anfangs ist der Stack leer. Zur Eingabe von ein paar Zahlen schreibt man z.B. hin:
23 7 9182"Zahlen" sind - nur im interpretierenden Zustand - neben den "Worten" der einzige weitere Datentyp. Sie werden vom Interpreter sofort im Stack abgelegt und danach nicht mehr von anderen Daten unterschieden. Beim Anlegen neuer Worte baut der betr. Compiler ("LITERAL") beliebige Stackposten, die von jenen als "Zahlen" verarbeitet werden sollen, ebenfalls in Form eines "Wortes" darin ein. Wobei auch die Zahlengewinnung im Forth wieder auf denkbar einfache Weise geschieht:
Jeder Text, der nicht bereits als "Wort" bekannt ist, gilt als "Zahl".Ist die entsprechende Umwandlung nicht möglich, bricht der Interpreter mit Fehlermeldung ab.
Zu Beachten: Zahlen im Forth sind zunächst nur die Ganzen Zahlen ohne jede
"Eigenschaft" - selbst die Bewertung mit oder ohne Vorzeichen geschieht allein durch die
verarbeitenden Worte.
Gebrochene Zahlen in Gestalt der Quotienten aus Ganzzahlen-Paaren können bei
mäßigem Aufwand z.B. mit Hilfe der "Skalierungsoperatoren"
bearbeitet und angezeigt werden. L4 stellt hierzu u.a. das
Vocabular "RATIONAL" bereit, in dem mit Reellen Zahlen gerechnet werden kann
und das ganz ohne die "floating point"-Operationen des Processors und deren
spezielle Datenformate auskommt, entsprechendes liegt als 'hi-level'-Ergänzung
auch für F4 vor; und es gibt Worte für "Fließkommazahlen" auf Grundlage
eben jener besonderen Processorbefehle - deren Resultate allerdings von weit
geringerer Genauigkeit sind: So einfache wie auch häufige Bruchzahlen wie
1/3, 1/10, "0,01" u.dgl. sind damit nicht, rsp nur mit kaum kalkulierbarem
Rundungsfehler darstellbar. Darum ist, im Gegensatz zu o.g. 'Reellen Zahlen',
die absolute Genauigkeit erlauben, der fp-Befehlssatz des Processors etwa zum
kaufmännischen Rechnen gänzlich ungeeignet! Beide Darstellungsformen
bleiben in der weiteren Betrachtung jedoch außer acht, hier sollen nur
die Ganzzahlen interessieren.
Nun geben wir mit dem "Punkt"-Wort (nur das Schriftzeichen für den Punkt) die jüngste, "obere" Zahl vom Stack aus
.Es erscheint die zuletzt eingegebene Zahl im Bild.
.Serscheint (L4) dieses Bild:
">D[2:10] 7 23"Die 9182 fehlt nun, da sie durch "." dem Stack zur Ausgabe entnommen wurde. .S läßt dagegen den Stack-Inhalt unverändert.
L4: Ausgabe mit der jüngsten Zahl ganz links.
Konventionen zur Bildausgabe dieses Wortes sind nicht festgelegt, meist wird allerdings
analog der üblichen Stack-Notation (s.u.) die umgekehrte Reihenfolge gewählt.
Ein Wort S., das die Ausgabe wie bei den Beispielen
und Lösungen besorgt und .S ersetzen kann, findet sich am Ende des Textes.
.S gibt mit dem ersten Zeichen den Systemzustand interpretierend ">" oder compilierend
"=" an, "D" für den Daten-Stack, dann die Anzahl Posten wie von DEPTH zurückgegeben,
und die gerade gültige Zahlenbasis (s.u.) als
Dezimalzahl. Es folgt der Stackinhalt, außer bei dezimaler Darstellung stets vorzeichenlos
hingeschrieben, der Übersicht halber auf 32 Posten begrenzt.
Die Bereitschaftsmeldung der Eingabe ("prompt") kann so umgeleitet werden, daß
diese Anzeige automatisch erfolgt:
also hidden ' .s idx>xec 4th>abs (ok) ! previous
Mit [OK] statt des .S stellt man auf dieselbe Weise die alte Betriebsart
ggf. wieder her. Wobei die genannten Worte hier zunächst unerklärt hingenommen
seien, rsp. ihre Bedeutung im System mit HELP... in Erfahrung gebracht werden mag.
Das in den Beispielen vielfach erscheinende .S ist dann oft entbehrlich.
Im F4 genügt umschalten mit {o} zwischen Stackdarstellung und einfachem 'Prompt'.
Die "Stack-Notation", auch "Stack-Diagramm", ist wesentlicher Bestandteil jeder Forth-Dokumentation. Sie beschreibt den Datenfluß anhand des Zustandes vor und nach Ausführung eines Wortes, eingefaßt in runde Klammern
( vorher -- nachher, Kommentar ).Die führende runde Klammer ist zugleich das Forth-Wort, das einen Kommentar einleitet, der bis zur ersten im Text erscheinenden umgekehrten runden Klammer reicht. Zeilenumbruch gilt hier beim ANS-Forth NICHT als Ende, bei den fig-Forth-Varianten geht der "("-Kommentar nicht über das Block-Ende hinaus, im F4 identisch mit einer Screenfile- rsp. Eingabe-Zeile.
Für "." könnte das Stack-Diagramm etwa so aussehen:
. ( N -- , erste Zahl vom Stack hinschreiben )Das "N" steht für irgendeine Zahl. Nach den Trennstrichen "--" bis zum Komma "," folgt der verbleibende Stackinhalt, hier also nichts, da die Zahl dem Stack nur entnommen wurde. Der Rest ist erläuternder Text. Zur besseren Übersicht wird jeweils immer nur der Bereich der betr. Stacks angegeben, in dem Veränderungen stattfinden. Eine ausführlichere Erläuterung findet sich im Glossar oder in der html-Dokumentation zur lib4th in "l4nte.html" (local).
Soll zwischen den einzelnen Beispielen der Stack geleert werden, gibt man das (selbstgebaute) Wort SP> ein.
Wegen dessen besonderer Bedeutung soll sich die Anordnung der Daten im Stack leicht beeinflussen lassen. Einige der dafür vorgesehenen Worte wollen wir uns ansehen:
SP> .S 777 DUP .SDie eingegebene Zahl erscheint jetzt doppelt. Hier das Stack-Diagramm von DUP,
DUP ( n -- n n , oberen Stackposten DUPlizieren )DUP ist hilfreich, wenn der obere Stackposten von irgendeinem Wort verarbeitet, zugleich aber für weitere Operationen noch bereitgehalten werden soll - im allgemeinen "verbrauchen" Forth-Worte ihre Parameter.
Ebenso nützlich ist SWAP
SWAP ( a b -- b a , die beiden oberen posten tauschen )Den Effekt zeigt das Beispiel
SP>
23 7 .S
SWAP .S
SWAP .S
Andere unentbehrliche Worte sind:
OVER ( a b -- a b a , zweiten stackposten copieren )
OVER .SOVER holt den zweiten Posten nach oben auf den Stack.
OVER .S
DROP ( a -- , oberen stackposten entfernen )
.SDROP entfernt den oberen Posten.
DROP
.S
ROT ( a b c -- b c a , dritten posten nach oben ROTieren )Obwohl bereits durch andere in einem System notwendige Worte darstellbar, ist ROT wegen seiner häufigen Verwendung immer vorhanden.
SP>
111 222 333 .S
ROT .S
ROT .S
ROT .S
Womit die allerwichtigsten und für viele Anwendungen bereits ausreichenden Operationen zur Umordnung des Daten-Stacks gegeben sind.
Beliebig tiefreichendes Rotieren erlaubt
ROLL ( nn nm ... n2 n1 n0 m -- nn ... n2 n1 n0 nm )ROLL copiert den m-tem Posten in die Position des Index m und rückt den Stackinhalt um einen Posten soweit auf, daß gerade noch die ursprüngliche Eintragung nm überschrieben wird. 0 ROLL bewirkt garnichts, 1 ROLL entspricht SWAP, 2 ROLL ist ROT.
PICK ( nn nm ... n2 n1 n0 m -- nn nm ... n2 n1 n0 nm )PICK holt den m-ten Posten nach oben, indem es den Index m durch jenen ersetzt. 0 PICK ist gleichbedeutend mit DUP, 1 PICK entspricht OVER. Der Index m zählt gewöhnlich ab Null für "tos", mitunter wird jedoch ab Eins gezählt (z.B. "F83").
Wo PICK und ROLL zusammen mit nur einfachen Datenposten gehäuft vorkommen,
sollte evtl. der betr. Programmverlauf auf die Möglichkeit günstigerer
Parameteranordnung für die einzelnen Worte überprüft werden, um
allzuvielen Stackmanipulationen aus dem Wege zu gehen.
Andererseits ist die allfällig pauschal gegen deren Einsatz paedagogisierende
blinde Polemik ganz und gar abwegig, so kann PICK z.B. äußerst effizient
"locale Variable" weitgehend ersetzen. Lassen sich damit Daten auch in den Stack
zurückgeben (L4/F4: PICK und ROLL mit negativem Index), werden
jene vollends entbehrlich.
Postenanzahl oder -Position spielen keine Rolle: Es ist restlos gleichgültig,
wie weit mit PICK in den Stack hineingegriffen wird. Auch das oft als Übel
beschriebene "stack dancing", das mit "LOCAL"s vermeidbar sei, ist eine eher abartige
Konstruktion, werden doch auch Locals stets über den Stack bearbeitet. Der
Begriff entspringt wohl mehr der naiven Vorstellung von Stacks als körperlich
vorhandener Stapel, wo nach einer gewissen Anzahl Operationen dem untrainierten
Programmierer die Muskulatur zu erlahmen droht.
Die Datenschaufelei im Stack ist unproduktiv, sie hat nur ordnende Funktion.
Wo sie durch günstigere Anordnung überflüssig gemacht werden kann,
erhöht sich die Ausführungsgeschwindigkeit oft ganz beträchtlich.
Die für solche Fälle gerne empfohlenen "Localen Variablen" lesen sich
im Quelltext wohl recht hübsch, Gewinn für die Programmausführung
entsteht gewöhnlich nur bei sehr großer Anzahl freier Datenregister
der MPU, bei IA32-Processoren Verursachen die 'Locals' gegenüber der direkten
Manipulation eher einen zumeist auch noch ganz erheblichen Zeitverlust.
Sehr hilfreich beim Entwurf komplizierter Worte ist Mitschreiben des Datenflusses in Stack-Anordnung:
Eingang Worte... Ausgang Position OVER OVER ROT p p p p p 0 tos u u u p p 1 nos p p u u 2 u u u 3
Einige weitere nützliche Stack-Operationen:
?DUP ( a -- a a | 0 , DUP nur, wenn a =/= 0 ist, '|' deutet eine Alternative an )
-DUP ( a -- a a | 0 , andere, traditionelle Schreibweise für ?DUP)
-ROT ( a b c -- c a b , rückwärts ROTieren )
2SWAP ( a b c d -- c d a b , doppelten posten tauschen )
2OVER ( a b c d -- a b c d a b , OVER eines doppelten posten )
2DUP ( a b -- a b a b , datenpaar DUPlizieren )
2DROP ( a b -- , die beiden oberen posten entfernen )
NIP ( a b -- b , zweiten posten entfernen, L4: SDROP = SWAP DROP )
TUCK ( a b -- b a b , oberen posten an dritte stelle copieren, L4: SOVER = SWAP OVER )Ausführliche Versuche mit diesen Worten und dazu eingegebenen Zahlen sind nun ratsam.
Nebenbei, krampfhaft "originelle" Namen wie TUCK oder PLUCK, oder FLOCK,
oder NIP, oder dergleichen mögen einem sparsamen Wortschatz mühevoll abgerungen
worden sein, welche Anstrengung ja durchaus gewürdigt sei, und doch kann dergleichen
nur lästig werden. Wenn solche Namen sich weder mit gängigen Fachworten noch
Worten der eher "normalen" Sprache einigermaßen leicht in Beziehung setzen lassen,
wird damit zu rechnen sein, daß das Betreffende weniger der Analyse unterzogen,
sondern schlicht und einfach vergessen werden wird. Wer will schon seine Zeit mit langweiligen
Gedächtnisleistungen zum Lernen zusammenhangloser Akronyme vergeuden. Derlei manieriertes
Zeug ist ebenso nervtötend, wie auch die Laber-Variante mit endlos langen Namen.
'Deskriptive' Wortnamen müssen nicht alles erklären, eben dazu gibt es das
"Glossar". Gemeinverständliche und plausible Worte existieren in hinreichender
Vielfalt für jeden Zweck in jeder Sprache...
Jede Aufgabe beginnt mit der Eingabe
SP> 11 22 33Dann wende man die bisher genannten Worte derart darauf an, daß jeweils die folgenden Werte im Stack erscheinen (hier von links nach rechts, "tos" ist rechts):
Das Umherschubsen von Zahlen im Stack wird auf die Dauer nicht sonderlich befriedigen, und so mag alsbald der Wunsch entstehen, damit irgendetwas Nützliches anzufangen. Also wenden wir uns den arithmetischen Operationen zu.
Die Arithmetik-Operationen entnehmen sämtlich die benötigten Zahlen der Reihe nach dem Datenstack und geben das Ergebnis dorthin zurück. Um etwa zwei Zahlen zu addieren, gibt man + ein:
2 3 + .
2 3 + 10 + .
Diese Schreib- und Vorgehensweise heißt "Postfix Notation" oder auch "Umgekehrte Polnische Notation", UPN, in der englischsprachigen Literatur "reversed polish notation", RPN. Sie zeichnet exakt dieselben Vorgänge auf, wie sie etwa beim Kopfrechnen anfallen. - Für solche, die 'real time' mit 'Echtzeit' übersetzen: 'Postfix Notation' ist nicht eine Methode zum besonders schnellen Versand von Musikaufzeichnungen.
Ihr konkreter Vorteil für eine Computer-Sprache besteht u.a. darin, daß sie
einer Rechenmaschine die Daten in einer Form zuführt, die die sofortige Verarbeitung
direkt aus dem Eingabestrom und nur mit Hilfe eines Zahlenstack erlaubt. (Nahezu) alle
Rechner arbeiten intern in eben dieser Weise. Den Gebrauch vereinfacht die Tatsache,
daß das lästige "Prioritäten"-Gerümpel anderer Notierungsformen
entfällt. Die im Schulunterricht gewöhnlich bevorzugte Schreibweise mit
Rechenoperationen zwischen den Zahlen ist einigermaßen weltfremd - wie etwa wird
handschriftlich addiert oder multipliziert? sie macht das Rechnen durch ihre Regeln der
Reihenfolge, Punkt vor Strich u.dgl, nur unnötig kompliziert.
Genauer betrachtet ist jede der drei Notierungen längst Gewohnheit,
begegnen sie uns doch im Alltag allenthalben, ziemlich gleichberechtigt
jeweils dort, wo sie ihren Platz haben. Dem Computer wird solches
Abwägen nicht zugemutet, man entschließt sich, und bei Forth
heißt das "UPN", nach dem Grundsatz, daß man immer erst haben
muß, womit man etwas anfangen will.
(M)ein klassisches Beispiel, wo die UPN das Rechnen besonders deutlich vereinfacht
Legt man den Ausdruck "r=a+b*wurzel(c+(d*e/(d-e)))" als Rechenanweisung zugrunde, wird die Gesamtoperation in Forth zu:
Die Operatoren - + * / :
30 5 - . \ 25=30-5 30 5 / . \ 6=30/5 30 5 * . \ 150=30*5 30 5 + 7 / . \ 5=(30+5)/7Einige besonders oft benötigte Kombinationen liegen als eigene Forth-Worte vor. Damit erhöht sich die Ausführungsgeschwindigkeit und der vom Programm benötigte Speicherplatz wird geringer gehalten:
1+ 1- 2+ 2- 2* 2/"2*" etwa ist die Zusammenfassung von "2 *".
10 1- .Wenn in letzterem Falle -1 zurückgegeben wird, sieht man eine der Merkwürdigkeiten, die auf die den Divisionsworten zugrundeliegenden Rechner-Operationen zurückzuführen sind. Ausgehend von der gewöhnlich bevorzugten Rundung des Ganzzahl-Quotienten in Richtung Null entsteht hier ein augenscheinlich 'falsches' Ergebnis, da die verkürzte Forth-Operation {2/} 'floored' arbeitet, d.h. nach negativ unendlich rundet. Zusammen mit dem Rest wird auch dies plausibel, -1 / 2 ergibt -1 und Rest 1, die Probe -1 * 2 + 1 belegt, das auch solch ein Ergenis schlüssig ist. Diese Rechenweise ist im Computer oft einfacher, mitunter auch vom Ergebnis her vorteilhaft (z.B. intern für die RATIONALen Zahlen der L4). Wo sie unerwünscht ist, behilft man sich im ANS-Forth mit {SM/REM}, das "normal" arbeitet.
7 2* 1+ . ( 15=7*2+1 )
-1 2/ . ( ei der daus.... )
Bei der Division beachte man, daß mit / der Divisionsrest verlorengeht.
15 5 / .Dies haben alle Computer-Sprachen gemeinsam. Wir werden uns später den Operatoren /MOD und MOD zuwenden, die (auch) den Divisionsrest angeben.
17 5 / .
Es ist nun an der Zeit, ein erstes kleines "Programm" in Forth zu schreiben. Das geschieht im allgemeinen dadurch, daß mit Hilfe der bereits bekannten ein neues Wort zusammengestellt wird. Forth-Programme erweitern auf diese Weise das System selbst, immer basierend auf dem bis dahin Vorhandenen. 'Vorwärtsreferenzen' als klassisches Hilfsmittel der Erzeugung von undurchdringlichem 'Spaghetti-Code' in Gestalt verworrener Programmquellen sind, wenngleich z.B. mit Hilfe von Variablen oder durch Manipulationen im Compilestack darstellbar, ganz und gar unüblich und bei planvollem Vorgehen kaum je erforderlich.
Nehmen wir ein Beispiel, mit dem sich der Durchschnittswert zweier Zahlen ermitteln läßt. Hierzu bedienen wir uns der Worte Doppelpunkt ":" ("colon") und Semicolon ";", mit denen ein neues Wort als typische Forth-Definition ("colon definition") eingeleitet rsp. abgeschlossen wird:
: AVERAGE ( a b -- avg ) + 2/ ;Immerhin... Dies war das erste Forth-Programm.
: ( <leerzeichen>name -- , beginn einer colon-definition )
; ( -- , abschluß einer colon-definition )
ANS-4th: Je nach Systemaufbau können von ":" an ";" u.U. steuernde
Daten im Stack übergeben werden. Der Datenstack muß innerhalb einer im
Aufbau befindlichen colon-Definition zwar in definierter, aber nicht unbedingt in
derselben Weise verfügbar sein, wie außerhalb. Im fig-Forth ist mit derlei
Störungen nicht zu rechnen.
Nur kurz sei auf die Möglichkeit vorübergehender Suspendierung
des Compile-Zustandes zwischen "[" und "]" hingewiesen, etwa
für eine Zwischenrechnung, deren Ergebnis als Festwert übernommen wird
..(forth).. [ latest pfa cfa ] literal ..(forth)..oder beim bedingten Compilieren, was - einmal mehr - in dieser Einführung nicht weiter verfolgt werden soll.
Probieren wir es:
10 20 AVERAGE . ( soll 15 ausgeben )Und, sowie ein neues Wort existiert, kann es seinerseits mit demselben Verfahren zum Aufbau weiterer neuer Worte benutzt werden. Zur Prüfung:
: TEST ( -- ) 50 60 AVERAGE . ;Man versuche, ein wenig mit Kombinationen der bekannten Worte in ähnlicher Weise herumzuspielen.
TEST
Um zu erfahren, was für Worte überhaupt verfügbar sind, ruft man WORDS auf, oder VLIST. Die Flut derart vorgeführter Namen soll aber nicht verunsichern. Relativ wenige davon werden ständig gebraucht. Für den Rest zieht man ggf. das Glossar zurate.
L4, F4:
Die Anzeige sehr langer Wortlisten kann mit der Leertaste angehalten und
mit jeder anderen wieder freigegeben werden. WORDS liefert sie
alphabetisch sortiert, VLIST in Reihenfolge ihrer Definition.
HELP wortname gibt jederzeit den zugehörigen Glossar-Eintrag
aus, sodaß man sich die Eigenschaften der seltener benötigten
Worte kaum zu merken braucht.
Umgekehrt gibt "V wortname" an, in welchem Vocabular ein Wort zu
finden ist.
ORDER zeigt nach "context:" die Wortliste an, deren Bestand gerade
aufgelistet wurde:
L4 schreibt die je zwei Posten der 'ambulanten' Vocabularstacks hin, dann die
im erweiterten VStack angelegte Suchordnung:
current:forth forth context:forth forthF4 gibt die beiden zugehörigen Such-Ketten aus:
cons rational bignum testvoc editor linux tools hidden ans forth
context :forth vt linux elf float complex hidden assemblerNach Hinschreiben anderer Vocabularnamen (VOCS zeigt diese an) gibt WORDS dann deren Wortliste aus. Zugleich wird das jüngstgenannte zu dem Vocabular, in welchem eingegebene Worte zuerst gesucht werden. Das vorherige Context-Vocabular wandert in den "Vocabular-Stack" - Beim Probieren werden benötige Vocabulare u.U. aus diesem besonderen, relativ kleinen Stack (L4: 2 Posten in der ersten, hier in betracht kommenden Stufe, 32 im eigentlichen Vocabularstack) hinausgeschoben und deren Definitionen plötzlich nicht mehr gefunden. Man gibt dann einfach nur die betr. Namen ein, um sie wieder in die Liste der zu durchsuchenden Vocabulare (vom Anfang her) einzureihen.
current :vt linux elf float complex hidden assembler forth
Das erste durch ORDER nach "current:" hingeschriebene Vocabular nimmt die neuen Defnitionen auf. Es wird nicht von "WORDS" oder "VLIST" erfaßt; mit DEFINITIONS kann das context-Vocabular dorthin übertragen werden. Man schreibt etwa
FORTH DEFINITIONS ( FORTH wird "context" und dann "current" )
Den Rest einer Division liefern /MOD als zweiten Stackposten nach dem Quotienten und MOD mit nur dem Rest im Stack.
SP>Zwei recht handliche Worte sind auch MIN und MAX. Sie lassen von zwei Zahlen im Stack nur die jeweils kleinere rsp. größere stehen.
53 10 /MOD .S
SP>
7 5 MOD .S
56 34 MAX .
56 34 MIN .
-17 0 MIN .
Weiter nützlich sind
ABS ( n -- abs(n) , betrag n )
NEGATE ( n -- -n , negation )
LSHIFT ( n c -- n<<c , n um c bits "links" schieben) RSHIFT ( n c -- n>>c , n um c bits "rechts" schieben )LSHIFT kann für die schnelle Multiplikation mit einer Zweierpotenz benutzt werden, RSHIFT entsprechend für die vorzeichenlose Division, der Division mit Vorzeichen dient RSHIFTA. Zum Beispiel:
RSHIFTA ( n c -- n>>c ) , "rshift" bei erhalt des vorzeichens) (L4, nicht ANS-4th)
<< ( n c -- n<<c , n um c bits "links" schieben, 'LSHIFT', F4) >> ( n c -- n>>c , n um c bits "rechts" schieben, 'RSHIFT', F4) a2>> ( d c -- d>>c ) , "rshift" bei erhalt des vorzeichens, 'RSHIFTA', F4)
: 256* 8 LSHIFT ;
3 256* .
Forth hat, wie im allgemeinen jede andere "höhere" Programmiersprache auch, keine Möglichkeit, den arithmetischen Überlauf irgendeiner Rechenoperation unmittelbar greifbar zu machen. Es bricht allerdings auch nicht mit irgendeiner schwachsinnigen Fehlermeldung ab, von wo aus erst recht keine Korrektur mehr möglich ist. Und immerhin kann mittels der nächst höheren Rechengenauigkeit, d.h. bei "einfachen" Zahlen Erweiterung und Rechnen mit "doppeltgenauen" Größen, solch ein Zustand recht leicht erkannt werden. Dies ist jedoch wenig effizient, und so bietet Forth "Mischoperatoren", wie z.B. M+ an, meist durch ein "m" im Namen gekennzeichnet, welche wir hier nicht behandeln, und die "Scalierungsoperatoren" */ und */MOD, bei denen solch ein Überlauf (in weiten Grenzen) garnicht erst auftritt:
Wenn der einfache Wertebereich zur Multiplikation nicht ausreicht, kann man */ benutzen, das intern mit doppeltgenauem Zwischenergebnis arbeitet. Der Divisor ist ggf. eine Scalierungsgröße, die ausreicht, das Ergebnis innerhalb der einfachen (L4: 32 Bit) Genauigkeit zu halten. Natürlich kann auch jede andere Zahl zur Division benutzt werden. Dann dient dieser Operator ganz allgemein der Zusammenziehung von * und /. In den folgenden drei Beispielen kommt nur mit */ das richtige Ergebnis zustande:
34867312 99154 * 665134 / .
34867312 665134 / 99154 * .
34867312 99154 665134 */ .
*/ ( a b c -- q , produkt a und b dividiert durch c )
*/MOD ( a b c -- r q , q:=a*b/c, r:=divisionsrest )Ohne weiteren Kommentar eine Anwendung von */MOD als Scalierungsoperator:
3,14 DROP DPL @ 5,7 DROP DPL @ ROT + BASE @ SWAP ^ DROP */MOD . .wo allein vermittels Ganzer Zahlen und entspr. Operationen ganzahliger und gebrochener Anteil eines Produkts aus "Fließkommazahlen" hingeschrieben werden. "dpl" hält die Position des Dezimal-Kommas (oder Punktes) der jüngsten Zahleneingabe, die dann zugleich auch doppeltgenau aufgenommen wird. "^" ist in diesem Beispiel die Potenz als doppeltgenaue Zahl. "drop" macht aus einer doppelten die einfachgenaue Variante.
M+ ( d n -- d' , d' := d+n, n vorzeichenerweitert )M+ addiert vorzeichenerweitert eine einfache zu einer doppeltgenauen Ganzzahl. Es ist von zentraler Bedeutung z.B. in (NUMBER) zur Zahlengewinnung aus dem Eingabestrom oder zur Feststellung rsp. Weitergabe des arithmetischen Überlaufs bei der Addition (Subtraktion).
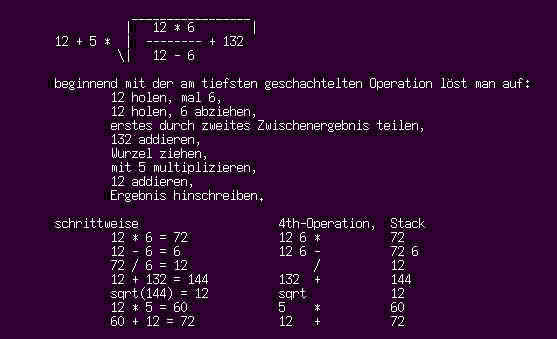
Wie löst man einen algebraischen Ausdruck auf? Beispielsweise
20 + (3 * 4)Versuchen wir es mit Kopfrechnen. Beginnend mit den am tiefsten geschachtelten Teilen eines Ausdrucks ermitteln wir das Teilergebnis und arbeiten uns in immer weitergefaßte Bereiche der Aufgabe "hoch". Hier fangen wir beim Produkt in der Klammer an und haben mit der Addition danach das Ergebnis:
3 4 * 20 +oder ein wenig anspruchsvoller:
100 50 + 2/ \ (100+50)/2"Ausdrücke" im Sinne gewöhnlicher Programmierhilfen kennt Forth nicht. Eine Gruppe von Rechenanweisungen löst man zur Kettenrechnung auf und rechnet sie der Reihe nach von "links nach rechts" aus. Das Ergebnis erscheint dann ohne Weiteres im Stack.
2 7 + 13 5 - * 3 * \ 3*((2+7)*(13-5))
Man forme die algebraischen in Forth-Ausdrücke um
Man definiere mittels der bekannten die neuen Worte
- ) (12 * ( 20 - 17 ))
- ) (1 - ( 4 * (-18) / 6) )
- ) ( 6 * 13 ) - ( 4 * 2 * 7 )
Die Antworten finden sich am Textende.
- ) SQUARE ( N -- N*N , quadratur )
- ) DIFF.SQUARES ( A B -- A*A-B*B , differenz zweier quadrate)
- ) AVERAGE4 ( A B C D -- [A+B+C+D]/4, arithmetisches mittel )
- ) HMS>SEC ( std. min. sec. -- secunden , summe und umrechnung )
"Zahlen" im Stack können alles mögliche darstellen, Forth ist
frei von eingeprägter Typisierung. Es ist Sache des jeweils
ausführenden Wortes, einen Datenposten geeignet zu deuten und ihn
entsprechend zu verarbeiten. Wird er als "Zahl" betrachtet, haftet ihm damit
z.B. eine Deutung "vorzeichenlos" oder "-behaftet" nicht automatisch bereits
an, ebensowenig irgendeine andere "Eigenschaft". Er kann somit auch als Zahlen-Code
eines Schriftzeichens dienen, z.B. im ASCII oder nach iso-8859-2, einer in
Mitteleuropa üblicherweise benutzten Codierung im Linux.
Man versuche
72 EMIT 97 EMITNun sollte "Ha" hingeschrieben worden sein, 72 ist Code für das große "H", 97 für das kleine "a". EMIT nimmt eine Zahl vom Stack und schickt sie in die Standard-Ausgabe, beim interaktiven Aufruf eines Forth-Programms gewöhnlich ein Consolen-Fenster. Die Codierung muß niemand auswendig lernen, es gibt dazu die Worte CHAR und [CHAR], die nach Überspringen aller evtl. führenden Leerzeichen das erste Schriftzeichen im Eingabestrom decodiert als Zahl in den Stack legen. Der Rest einer ggf. längeren Zeichenfolge wird verworfen.
CHAR W .Das Wort ist definiert:
CHAR % DUP . EMIT
CHAR Andreadoria DUP .
32 XOR EMIT
: CHAR BL WORD COUNT DROP C@ ;[CHAR] verwendet man, um den Zeichencode als später verfügbare Zahl ("literal") in ein Wort zu compilieren.
CHAR ( <leerzeichen>name -- char , Code eines Schriftzeichens )oder (L4)
CHAR ccc( -- char , Code eines Schriftzeichens )
EMIT alleine würde die Textausgabe allzu mühselig machen. Glücklicherweise gibt andere Wege
: TOFU ." Kutte's Jummiklops " ;Das Wort ." schickt den Text nach dem ersten Leerzeichen (das nötig ist, damit es als Wort erkannt werden kann) bis vor das abschließende Anführungszeichen in die Ausgabe. Soll er in einer neuen Zeile erscheinen, schreibt man vorher CR hin.
TOFU
: SPROUTS ." Junges Gemüse." ;Ein Leerzeichen kann mit SPACE ausgegeben werden, eine gewisse Anzahl davon mit SPACES
: MENU
CR TOFU CR SPROUTS CR ;
MENU
CR TOFU SPROUTS
CR TOFU SPACE SPROUTS
CR 10 SPACES TOFU CR 20 SPACES SPROUTS
KEY ist das Gegenstück zu EMIT. Es wartet, bis eine Taste betätigt wird und liefert den Code des entsprechenden Zeichens zum Stack.
: TESTKEY ( -- )Hinweis:
." Taste: " KEY CR ." Code: " . CR ;
TESTKEY
Zusammengefaßt
EMIT ( char -- , schriftzeichen ausgeben )
KEY ( -- char , tastaturcode empfangen )
SPACE ( -- , leerzeichen ausgeben )
SPACES ( n -- , anzahl n leerzeichen ausgeben )
CHAR ccc( -- char , zeichencode holen )
CR ( -- , nächsten zeilenanfang aufsuchen )
." ( -- , text bis zum nächsten anführungszeichen ausgeben )
lib4th-Programme - wie die meisten Forth-Systeme - enthalten Worte zur
Eingabe-Umleitung, sodaß diese auch aus einer Datei aufgenommen werden kann.
Damit lassen sich vorher bereits verfaßte Texte ohne weiteres anstelle der
direkten Eingabe verwenden. Bei dieser einfachsten Zugriffsform muß dann
aber der gesamte Programmverlauf in der Datei angelegt sein, Rückkehr zum
Interpreter und zur Tastatureingabe ist etwa mit QUIT möglich.
Eher gewohntem, zudem standardmäßigem Vorgehen entspricht das 'Laden'
(Compilieren oder Ausführen) von Programmtexten aus Files mit Hilfe besonderer
Worte wie LOAD, INCLUDED, &c.
Versuchen wir es mit einem kleinen Beispiel. Dazu ist ein Editor aufzurufen,
mit dem sich ungewürzter, einfacher Text erzeugen läßt, ohne
"Formatierung" oder anderen Schnickschnack, einzig mit der geeigneten
Markierung für das Zeilenende.
Die klassischen, Forth-typischen " Block-Files " rsp. " Screen-Files "
benötigen selbst diese nicht, was, wo bei all dem großartigen Fortschritt
sämtlicher Hersteller eben jene nicht einmal imstande sind, sich auf einen Code
für das Ende von Textzeilen zu einigen, die weitgehende Systemunabhängigkeit
wenigstens der grundlegenden Programmteile zur Textverarbeitung erlaubt. Es bedarf
dazu allerdings eines hinreichend einfachen Editors
zum Umgang mit solchermaßen unformatiertem Text. Trotz denkbar geringer Anforderungen -
die Anzeige-Breite muß einstellbar sein - sind doch nur wenige Editoren dafür
zu gebrauchen. Manche e-mail-Programme bringen dergleichen mit, 'vi' ist entsprechend
konfigurierbar.
Gehen wir sicherheitshalber von zeilenweise angeordnetem Text aus:
So gibt man etwa ein
\ Forth Beispielprogramm, Autor: (ich) |
INCLUDE ( ccc<spaces> -- , text vom file mit namen ccc ausführen )INCLUDE gibt an, daß die Eingabe ab sofort einem File entnommen werden soll. Sei obiges Beispiel unter dem Namen "probe" in das aktuelle Verzeichnis - vom Forth-System aus gesehen - gesichert worden, dann kann es (im Linux mit führendem "./") compiliert werden
INCLUDE ./probeINCLUDE ist in keinem der vielen 'Standards' vorgesehen, im ANS-4th gibt es das etwas unbequeme
INCLUDED ( p u -- , vom file mit namen(p,u) compilieren )Andere haben etwa USING für 'Block-Files', das gleichartige Parameter erwartet und evtl. noch die Nummer der 'Screen', die compiliert werden soll. Nahezu alle 4th-Systeme kommen hier mit eigenen Varianten, die in irgendeiner Form die Bedienung erleichtern sollen.
test.squareund es wird sich zeigen, daß die Datei tatsächlich genau wie eine Eingabe aus der Tastatur aufgenommen wurde.
In Forth gibt es nun die für Programmiersprachen sehr ungewöhnliche Möglichkeit, durch FORGET einen Compiliervorgang rückgängig zu machen.
FORGET SQUAREentfernt SQUARE und alles, was danach compiliert wurde, aus dem Speicher. Versuche, nun "test.square" erneut auszuführen, werden mit einer Fehlermeldung quittiert.
Worte lassen sich mit identischen Namen "überdefinieren"; sie haben von
da an Vorrang gegenüber der jeweils älteren Variante. Soweit bereits
compiliert, gelten weiterhin die ursprünglichen Definitionen, und nach
FORGET einer jüngeren wird die vorherige wieder "sichtbar" (in etwas
merkwürdiger Ausdrucksweise wird dies oft "overloading" genannt - was
nichts mit "Überlastung" zu tun hat). Zusammen mit den
"Vocabularen", die wir weiter unten
kurz betrachten werden, ergeben sich daraus interessante Möglichkeiten.
FORGET ist nicht unbedingt erforderlich, doch wird es insbes. bei
Entwurf und Prüfung neuer Programme recht nützlich.
L4 & F4:
FORGET eines unbekannten Wortes hat keine Fehler-Aktion zur Folge.
Wenn ein Wort nicht da ist, ist es weg, genau das soll FORGET sicherstellen,
Fehlen eines zu tilgenden Wortes ist darum nicht Fehlerbedingung.
Bringen wir ein paar Änderungen an, sichern und compilieren die Datei erneut:
Der Nutzen von FORGET rsp. MARKER ist nun aber keineswegs auf programmierende Kammerjäger beschränkt. Bei begrenztem Speicher können etwa 'Overlays' interessant werden, d.h. auswechselbare Ergänzungs-Programme. Wiederholung z.B. einer Folge { LOAD teilprogramm, Ausführen, FORGET teilprogramm } oder noch einfacher, die Definition eines gleichlautenden MARKER in jeder Overlay-Quelle bieten sich dafür als ausgesprochen leicht zu handhabende Hilfsmittel an.
Nebenbei, "dictionary" heißt hier eigentlich "dictionary space", und bezeichnet zunächst im weitesten Sinne den Speicherbereich, in dem sich Forth-Worte oder auch Daten befinden rsp. wohin solche ggf. compiliert werden. In etwas enger gefaßter Lesart steht "dictionary" für die Gesamtheit vorhandener Worte.
Bei größeren Projekten mag es sinnvoll werden, eine besondere Datei nur für die INCLUDEs zu verwenden, und es werden mitunter Bedingungen auftreten, wo einzelne Worte ohne besondere Vorkehrungen mehrmals geladen, d.h. compiliert, würden. Für solche Fälle gibt es INCLUDE? (nicht ANS-4th, und die Anzahl ähnlicher Worte ist Legion), das ein File nur dann lädt, wenn der zusätzlich angegebene Wortname in der augenblicklichen Such-Ordnung (im "context", ggf. einer Folge von Vocabularen) nicht existiert.
INCLUDE? www ccc( -- xx , include file ccc nur, wenn wort www unbekannt )Zum Beispiel
FORGET probeNachdem darin der MARKER entfernt wurde, wird nur das erste INCLUDE? das File tatsächlich auch laden. - Man vergewissere sich etwa durch einfügen einer schreibenden Kommentarzeile, mit .( statt (.
INCLUDE? SQUARE ./probe
INCLUDE? SQUARE ./probe
Daten werden für gewöhnlich im Stack sowohl bereitgehalten als auch bearbeitet, weshalb man mit Forth von "Variablen" weit weniger Gebrauch macht, als bei den gewöhnlichen Programmierhilfen. Variable werden hier vor allem ihrem ureigenen Zweck (und Namen) entsprechend gebraucht, zur Aufbewahrung veränderbarer Daten, auf welche von verschiedenen Stellen im Programm zugegriffen wird.
VARIABLE ccc( -- , variable definieren ) ( -- p , ausführen )VARIABLE ist ein "Definitionswort", legt also ein neues Forth-Wort an. Etwa
VARIABLE dingsdaerzeugt mit "dingsda" die namentliche Identifikation der Speicherstelle p, mit p als "Pointer" darauf, und reserviert dort den Platz für eine "Zelle".
513 dingsda !
dingsda @ .
@ ( p -- n , inhalt n der speicherzelle bei p lesen )
! ( n p -- , n in speicherzelle am ort p ablegen )
VARIABLE ccc( -- , mit ccc benannten speicherplatz für eine 'zelle' einrichten )Hilfreich bei der Untersuchung von Variablen ist
? ( p -- , inhalt der speicherstelle p ausgeben )
dingsda ?Man könnte sich auch ein U? definieren
: U? @ U. ;
Es werde etwa ein Spiel programmiert, wo die Anzahl erreichter "Punkte"
mit ihrem bis dato höchsten Betrage in einer Variablen gespeichert
werden soll. Wird eine neue Punktzahl gemeldet, kann diese mit dem
gespeicherten Höchstwert verglichen werden. Eingabe wie im ersten
Beispiel
VARIABLE HIGH-SCORE |
123 REPORT.SCORE
9845 REPORT.SCORE
534 REPORT.SCORE
@ und ! arbeiten einheitlich mit ganzen "Zellen".
C@ und C! sind die Forth-Worte für den Zugriff auf
8-Bit-Posten, das "C" ist aus "Characters" abgeleitet, da man
ursprünglich ein Schriftzeichen für fix mit 8 Bits indizierbar
hielt. Es gibt nun aber weit mehr als 256 Schriftzeichen, und als diese
befremdliche Tatsache hinreichend deutlich wahrgenommen wurde, "erfand" man
andere Methoden, die mit der ISO-Codierung oder auch us-ASCII vorzugsweise,
aber durchaus nicht immer in konfliktfreier Gemeinschaft existieren.
Die gern gewählte Ersetzung
COUNTfür
1+ dup 1- c@ist riskant, da keineswegs feststeht, daß Zeichencode und Zähler einer als "string" gespeicherten Zeichenfolge identischen Formats sind. Jedenfalls sollte, um Problemen mit der 'Internationalisierung' aus dem Wege zu gehen, die fiktive Beziehung "Schriftzeichencode = 8-Bit-Daten" NICHT fest in Programme eingehen!
Systeme mit größeren Zellen bieten zumeist auch Worte zum Zugriff auf 16-Bit-Posten an, etwa W@ und W!
+! ( n p -- , wert n zu speicherstelle p addieren )ist ein oft gebrauchtes Wort, das Lesen, Addieren und Schreiben an einer Speicherstelle effizient zusammenfaßt.
20 dingsda !Üblicherweise werden zusätzlich Varianten der VARIABLEendefinition angeboten, etwa ARRAY. Auch CONSTANT gehört in gewissem Sinne dazu, das eine Variable definiert und dabei zugleich besetzt, deren Aufruf dann statt einer Adresse den Inhalt zum Stack bringt. INTEGER und VALUE sind ähnlich. Die auf eine auswechselbare Basisadresse bezogenen "USER"-Variablen sind u.a. als Grundlage zum inneren, d.h. nicht durch ein umgebendes System getragenen "Multitasking" (der gleichzeitigen oder zeitlich eng geschachtelt unabhängigen Ausführung von Programmteilen) nahezu überall ebenfalls vorhanden.
5 dingsda +!
dingsda @ .
Wir haben in den VARIABLEn auch ein deutliches Beispiel zur - oft eher verborgenen - Verwendung von "Pointern", die gern als gefürchtete Hürde beim Programmieren beschrieben werden, nichtsdestoweniger aber eine überaus einfache und konsequente Form der Datengewinnung darstellen rsp. jene ermöglichen. Der "Pointer" ist im Forth die weitaus bevorzugte Form der Daten-Referenz, die u.a. das ständige Umherspeichern der wirklichen Daten erspart - und damit nicht zuletzt auch die zumeist in der MPU des betr. Rechners selbst angelegte Optimierung auf schnellen Programmablauf besonders fördert. Das ganz zu unrecht so furchtsam behandelte Thema der "Pointer-Arithmetik" erledigt sich im Forth weitgehend von selbst und wirft in Wahrheit nicht die geringsten Probleme auf, erspart sie eher! Allerdings, wie schon so oft, ein wenig Übung wird auch hierbei ratsam sein.
|
Eine Warnung zur Arbeitssicherheit: Einfache Schutzmaßnahme ist, (Forth-)Programme, deren Sicherheit für solche Fälle nicht verläßlich vorhergesagt werden kann, im Linux z.B. stets nur aus einem gering privilegierten "user-account" heraus zu starten und Arbeitsdaten mehrfach abzulegen. Wenn aber für etwa den direkten Zugriff auf einen i/o-Port (Drucker-Schnittstelle o.dgl.) "root"-Rechte unbedingt erforderlich sind, ist es ratsam, diese besonderen Rechte möglichst bald und unwiderruflich aufzugeben, bei 'suid'-betriebenen Programmen etwa mit Hilfe der Syscalls-Folge getuid und setuid, wie sie in F4 und L4 durch {real-user} als Forth-Wort bereits vorhanden ist. Dieselbe Gefahr besteht bei sehr vielen anderen Programmiersprachen auch, BASIC etwa, oder "C" ohnehin. Sei's drum, Thema hier ist Forth, und Forth soll den Programmierer gerade frei von allen Beschränkungen halten, ihm also auch den Zugriff auf ausnahmslos alle Ressourcen eines Rechnersystems ermöglichen. Umsonst gibt es das nicht! Als sicherlich zumutbarer Preis wird vor allem entsprechende Sorgfalt gefordert. Eine Eigenschaft des "interaktiven incrementellen Compilers", die Möglichkeit nämlich, jedes einzelne Wort unmittelbar nach dem Compilieren sofort auf Richtigkeit zu prüfen, hilft hierbei, und trägt dazu bei, daß typischerweise in Forth sehr zuverlässige Programme entstehen. |
|
Da Forth sich in jedem Detail frei gestalten läßt, ist auch die Natur möglicher Fehlersituationen vom System her zunächst unbekannt. Dies erklärt, warum hier das automatische Abfangen von "Fehlern" nur an wenigen Stellen bereits vordefiniert ist. Es stehen jedoch umfassende und leicht handhabbare Hilfsmittel für die Fehlerbehandlung zur Verfügung, die an den entsprechenden Stellen unbedingt in Programme aufgenommen werden sollten. Nochmals der Hinweis, daß selbst ein völlig fehlerfreies Programm längst noch nicht sicher gegen fehlerhafte Benutzung sein muß, und daß darum Schutz auch gegen versehentliche Fehlbedienung unerläßlich ist. |
Einmalig festgelegte Zahlen, die z.B. eine Programmvariante steuern und an vielen Stellen abgefragt werden, die aber, ist das Programm einmal compiliert, nicht mehr geändert werden, sind "Constante". Hierfür gibt es ein entsprechendes Definitionswort, mit dessen Hilfe solche Zahlen namentlich identifizierbar werden.
CONSTANT ccc( n -- , benannten speicherplatz einrichten und mit n besetzen )Bei Aufruf seines Namen gibt ein solches Wort den bei dessen Definition vorgelegten Zahlenwert im Stack zurück. Jener kann nachträglich nicht mehr geändert werden (L4, manche Systeme erlauben auch die Änderung von CONSTANTen).
128 CONSTANT MAX_CHARSBequem daran ist, daß bei veränderten Gegebenheiten nur die CONSTANTe selbst am Orte ihrer Definition anders besetzt werden muß, ihr Vorkommen im Programm ist damit automatisch angepaßt. In der Ausführungszeit sind CONSTANTe gewöhnlich ein wenig langsamer, als direkt als Zahlen ("LITERAL") compilierte Werte, die Variante INTEGER (L4) ist ebensoschnell und vor dem jeweiligen Compilationsort noch änderbar; wo sie einmal compiliert wurde, kann auch sie nicht mehr verändert werden.
MAX_CHARS .
Hierzu das Beispiel INTEGER, das
mit TO-INTEGER oder =: änderbare und beim erstmaligen Aufruf
ggf. neu einzurichtende Constante definiert, die beim Aufbau eines Wortes als
Festwert (LITERAL) unmittelbar in den Code übernommen werden. Zum
Verständnis dieses Definitionswortes sehe man sich seine Bestandteile im
Glossar an. - Die in L4 vorhandenen INTEGER können mit TO verändert
werden.
Damit zeigt sich auch, wie Definitionsworte selbst Worte erzeugen können,
die ihrerseits compilierende Funktion haben, hier nur durch LITERAL,
grundsätzlich aber ohne Einschränkung. Der Schlüssel dazu ist
das Wort "IMMEDIATE".
: INTEGER ( zahl <leerzeichen>name -- )und, ebenfalls in vereinfachter Definition
CREATE , IMMEDIATE \ im fig-Forth steht hier <BUILDS statt CREATE
DOES> @ POSTPONE LITERAL ; \ fig-Forth, L4, sonst LITERAL von STATE abhängig machen
: TO-INTEGER ( zahl <leerzeichen>name -- , INTEGER neu besetzen )
' >BODY ! ; IMMEDIATE ( L4: ' aus dem ANS-4th-Vocabular, nicht immediate! )
: =: ( zahl <leerzeichen>name -- )womit eine INEGER geändert oder, wenn sie noch unbekannt ist, automatisch neu eingerichtet wird, ähnlich dem LET anderer Programmiersprachen, nützlich u.a. für Vorgabewerte innerhalb von Programmen.
>IN @ >R BL WORD FIND IF >BODY !
ELSE DROP R@ >IN ! INTEGER THEN R> DROP ;
567 =: fünfsechssieben
...die dem System allein durch ihr Vorhandensein ein gewisses Vorgehen aufzwingen, sind im
Forth die reine Kulturschande, grundsätzlich geradezu sittenwidrige Femdkörper.
Eine irgendwelchen Daten eingeprägte Typisierung ist (im vorliegenden Kontext) reine
Fiktion, und so bringt Forth von sich aus dergleichen nicht mit. Die geeignete Bewertung von
Daten bleibt den jeweils damit arbeitenden Worten überlassen. 'Datentypen' als Element
der Programmier(er)-Sicherheit lassen sich aber mit Hilfe der Kombination
{ <BUILDS ... DOES> }
des fig-Forth sehr leicht darstellen, mit { CREATE ... DOES> }
der späteren Standards etwas umständlicher:
Jedes neu aufgebaute Definitionswort erzeugt bei Verwendung neben dem Datenteil des damit gebildeten
Wortes auch eine wie auch immer geartete Referenz in die Ausführungsvorschrift nach dem "DOES>".
Mit dieser Referenz ist ein solches Wort als "Typ" eindeutig identifizierbar. Es gilt "nur", jene
ebenso eindeutig zu ermitteln. Im fig-Forth ist die betr. Stelle die "pfa"
('parameter field address'), welche Adresse dort mit { ' } sofort zur Verfügung
steht. Andersartige Systeme bereiten dagegen mitunter Schwierigkeiten, insbes. wenn solche Interna
unzureichend beschrieben sind. In der "lib4th" steht mit {idx>do} ein Wort zur Verfügung,
das die Einsprungstelle in den auszführenden Code liefert und damit auch die eindeutige
Identifikation. Übergibt man nun mit Hilfe von {'} statt der Werte ein 'Execution Token',
z.B. die "pfa" (fig-4th, F4) oder den Wort-Index (L4), wird die
Typprüfung innerhalb anderer Worte möglich. O.g. "CONSTANT"e könnte im fig-Forth
(F4) folgendermaßen definiert werden:
Beispiel für L4:: CONSTANT \ name der neuen definition
<BUILDS \ einrichtungsvorschrift:
, \ zahl ins dictionary compilieren
DOES> \ ausführungsvorschrift:
@ \ datenposten von der mit DOES> übergebenen adresse holen
; \ definition des definitionswort beenden
0 integer nnnWo geeignete Unterstützung fehlt, kann man sich beim Aufbau eines Definitionswortes etwa folgendermaßen behelfen:
' nnn idx>do forget nnn
integer dointeger ( ausführungsadresse in 'dointeger' )
: add-integer ( ix1 ix2 -- n )
over idx>do over idx>do
dointeger dup d=
if execute swap execute +
else abort" Parameter nicht INTEGER-Typ" endif ;
123 integer 123
456 integer 456
' 123 ' 456 add-integer .
VARIABLE doint ( kontrollwert vorbereiten )wobei das Verfahren sehr von der jeweiligen Forth-Variante abhängt.
: INTEGER
CREATE , IMMEDIATE
DOES> [ here doint ! ] ( kontrollwert sichern )
@ POSTPONE LITERAL ;
doint @ integer dointeger ( aequivalent zu obigem beispiel )
Wir beschäftigen uns nun mit logischen Entscheidungen und damit aufgebauten Programm-Strukturen.
Zunächst einmal suchen wir die Antwort auf Fragen der Art "Ist der Wert groß genug?", "Trifft die Annahme zu?", u.dgl.
23 71 = .Der erste Versuch gibt "0" zurück, im Forth FALSE genannt, definiert als Zahl, die durch einen Datenposten repräsentiert wird, in dem alle Bits auf 0 stehen, der zweite liefert "-1", TRUE, repräsentiert durch einen Posten, in dem alle Bits mit 1 besetzt sind. Sie existieren mit diesen Namen auch als Forth-CONSTANTe.
18 18 = .
Mit TO (ANS-4th) lassen sich einem VALUE Werte zuweisen. L4: Das ALGOL entlehnte =: kann VALUEs oder INTEGER verändern und richtet mit dem vorgelegten Wert ggf. automatisch eine neue INTEGER ein, falls der Name noch nicht definiert war.
Auch "<" und ">" sind Logikoperatoren
23 198 < .
23 198 > .
254 15 > .
Ein drolliges Beispiel aus der "Zivilisierten Welt"
In Kalifornien (U.S.A.) darf man ab 21 Jahren alkoholische Getränke konsumieren. Ein einfaches kleines Programm könnte dem dortigen Kneipier die Arbeit erleichtern: DRINK? ( alter -- flag , darf diese person trinken? )
20 > ;
20 DRINK? . 21 DRINK? . 43 DRINK? .
Da solche Vergleiche besonders oft anfallen, stehen in Forth noch Abfragen zur Verfügung, ob eine Zahl gleich, größer oder kleiner Null ist
23 0> . ( schreibt -1 )Diese Operationen sind stets schneller, als der explizite Vergleich mit Null.
-23 0> . ( schreibt 0 )
23 0= . ( schreibt 0 )
-23 0< . ( schreibt -1 )
Bitweise Verknüpfungen von Zahlenposten erlauben die Boole'schen Operatoren OR, AND, und NOT, das nicht mehr elementare XOR gibt es ebenfalls als Forth-Wort. Zusammen mit 0= und den o.a. Flag-Werten können sie bei konsistentem Gebrauch auch aussage-logische Operationen darstellen: Die Logik-Operationen führen ein Zwitterdasein, zum einen für die logische Entscheidung, zum andern als Bit-Operationen. Dies wird durch die genannte Festlegung ihrer Bit-Darstellung möglich, zusammen mit der Definition von "NOT" als Umkehr aller Bits eines Datenposten.
OR gibt nur dann FALSE zurück, wenn beide Eingangsposten FALSE sind;
TRUE TRUE OR . TRUE TRUE AND . TRUE TRUE XOR . TRUE FALSE OR . TRUE FALSE AND . TRUE FALSE XOR . FALSE TRUE OR . FALSE TRUE AND . FALSE TRUE XOR . FALSE FALSE OR . FALSE FALSE AND . FALSE FALSE XOR .
TRUE .NOT kehrt die Bit-Werte um (heißt darum im ANS-4th auch INVERT).
TRUE NOT .
56 3 > 56 123 < AND .Logikoperatoren können in Kombination benutzt werden.
23 45 = 23 23 = OR .
Die zugehörige Stack-Notation:
< ( a b -- flag , true flag wenn A kleiner B )
> ( a b -- flag , true flag wenn A größer B )
= ( a b -- flag , true flag wenn A gleich B )
0= ( a -- flag , true wenn A null ist )
OR ( a b -- c , bitweise OR-verknüpfung A mit B )
AND ( a b -- c , bitweise AND-verknüpfung A mit B )
NOT ( flag1 -- flag2 , bit-umkehr, flag-wert umkehr )
Man entwerfe ein Wort LOWERCASE?, das TRUE zurückgibt, wenn eine Zahl im Stack innerhalb des ASCII-Wertebereichs für Kleinbuchstaben liegt. ASCII 'a' ist mit 97 codiert, die Buchstaben folgen kontinuierlich weitergezählt bis ASCII 'z' mit dem Code 122. Das neue Wort ist an den Schriftzeichen
A ` a q z {zu prüfen. Beispielsweise
CHAR A LOWERCASE? . ( 0 )Antworten hierzu am Textende.
CHAR a LOWERCASE? . ( -1 )
Wir werden nun die gerade kennengelernten Flag-Worte verwenden, um damit
Entscheidungsstrukturen zur Beeinflussung des Programmverlaufs aufzubauen
("control flow words"). Das sind Worte, die einen Flagwert auswerten und
davon abhängig ggf. den Sprung in einen anderen Programmteil veranlassen.
Am Rande der Hinweis, daß Puristen auf der Feststellung bestehen, Schleifen
und bedingte Konstruktionen welcher Art auch immer seien unnötig, sofern nur
betr. Proceduren bedingt verlassen werden könnten. Wohl wahr - doch in der
Idee zwar extrem einfach, in der konsequenten Ausführung aber ausgesprochen
umständlich und darum hier nicht weiter verfolgt. Andererseits verdient der
Grundgedanke durchaus Beachtung, denn durch Abspaltung von Schleifen/-Teilen sind
oft auch bemerkenswerte Vereinfachungen zu erzielen.
Es wird das Wort .L definiert
: .L ( flag -- , logikwert hinschreiben )und
IF ." TRUE"
ELSE ." FALSE"
THEN ." im stack." ;
0 .Lworan sich das Verhalten bei der einfachen Fallunterscheidung mit IF/ELSE zeigt: Kommt TRUE an, wird der Teil unmittelbar nach IF durchlaufen und mit einem Sprung hinter THEN (oder ENDIF, das die traditionelle, sinnfälligere Bezeichnung darstellt) fortgesetzt. Bei FALSE erfolgt von IF aus der Sprung unmittelbar hinter ELSE mit Fortsetzung direkt in den Bereich nach THEN.
FALSE .L
TRUE .L
23 7 < .L
23 .Lals TRUE behandelt wird. Hier stoßen wir auf die Eigenheit aller Forth-Worte, die Flags auswerten und nicht selbst eine binäre Logikoperation darstellen. Diese bewerten jeden von Null verschiedenen Wert mit TRUE. - Einen "ordentlichen" Flagwert macht daraus z.B. "0= 0=".
Wo der ELSE-Teil nicht erforderlich ist, läßt man ihn einfach weg und schreibt z.B. nur
: KNETE? ( betrag -- )
1000 > IF ." ZU TEUER!" THEN ;
531 KNETE? .
1021 KNETE? .
Der Standard beschreibt außerdem eine Mehr-Wege Fallunterscheidung, die in vielen Forth-Varianten enthalten ist, auch in L4. Sie ist allerdings meist nur die vereinfachte Schreibweise einer entsprechend tief geschachtelten IF/ELSE-Struktur, evtl. mit einem leicht optimierten Abfragewort, das das OF auf Code-Ebene ersetzt ('?CASE' in L4, '=IF' bei F4):
: OF POSTPONE OVER POSTPONE = POSTPONE IF POSTPONE DROP ; IMMEDIATEwomit OF die Wortfolge compiliert
OVER = IF DROPDas "POSTPONE" darin sorgt dafür, daß das jeweils folgende Wort erst bei Ausführung von OF in das im Aufbau begriffene Forth-Wort compiliert wird, OF selbst ist also ein Compiler, wie viele andere der "immediate" deklarierten Worte:
: TESTCASE ( N -- , aktion entspr. N )geprüft:
CASE
0 OF ." Nur 'ne NULL!" ENDOF
1 OF ." Alles EINS!" ENDOF
2 OF WORDS ENDOF
DUP . ." Ungültige Eingabe!"
ENDCASE CR ;
0 TESTCASEL4 und F4 bieten mit CASE: eine effizientere Variante an, mehr dazu im entspr. Glossar oder mit HELP CASE:.
1 TESTCASE
5 TESTCASE
Man entwerfe ein Wort DEDUCT, das einen Betrag von einer Variablen mit dem
aktuellen Kontostand subtrahiert. Der Saldo (die Differenz) werde in EURo
angenommen. Er soll ausgegeben werden, dazu ein Warnhinweis bei Pleite.
Ansatz:
VARIABLE KONTOanwendbar etwa:
: DEDUCT ( n -- , n vom saldo abziehen )
???????????????????????? ( das ist die aufgabe :)
;
300 KONTO ! ( anfangsbestand )Antworten am Textende.
40 DEDUCT ( 260 )
200 DEDUCT ( 60 )
100 DEDUCT ( -40 und warnung! )
Schleifen sind Kontrollstrukturen, bei denen ein Programmteil durchlaufen wird, an dessen Ende - zumeist von einer Entscheidung abhängig - Rücksprung zum Anfang erfolgt.
Das Wortepaar BEGIN .. UNTIL bildet solch eine Schleife, wobei das UNTIL mit TRUE-Flag deren bedingtes Verlassen erlaubt.
: COUNTDOWN ( N -- )COUNTDOWN zählt von einem übergebenen Anfangswert an abwärts bis Null. - Frage am Rande: Was geschieht bei Angabe einer negativen Zahl? Korrektur?
BEGIN
DUP . CR ( zahl vom stack ausgeben )
1- DUP 0< ( solange sie positiv ist )
UNTIL ;
16 COUNTDOWN
Bei festliegender rsp. zuvor im Programmverlauf ermittelbarer, bekannter Anzahl Durchgänge bietet sich auch DO...LOOP an.
: HAPPAHier wird erst "ba" ausgegeben, dann viermal das Textstück "na".
." ba" 4 0 DO ." na" LOOP ;
Die Anzahl Schleifendurchläufe ist gleich der Differenz
"Obergrenze - Anfangswert", der Index beginnt mit dem Anfangswert.
Vorsicht bei der Grenzenangabe: Wenn sie in falscher Reihenfolge geschieht,
dauert es u.U. sehr lange bis zum Verlassen der Schleife, LOOP zählt
vorzeichen- und gnadenlos immer nur eins weiter...
F4: Abbruch beliebiger Programmteile
ist jederzeit mit Taste CTRL"\" möglich.
Etwas "Zeichen-Graphik"
: PLOT# ( n -- )
0 DO
[CHAR] - EMIT
LOOP CR ;
CR 9 PLOT# 37 PLOT#
Der Laufindex kann mit dem Wort I gelesen werden, der einer unmittelbar übergeordneten Schleife mit J, mit L4/F4 sind durch NI darüberhinaus fortlaufend numeriert alle weiteren Indices greifbar (nicht ANS-4th), 0 NI entspricht I.
Ausgabe eines wählbaren Teils des aktuellen Zeichensatzes:
: .ASCII ( ende anfang -- , zeichensatz ausgeben )oder (L4) für den ganzen gerade eingestellten Zeichensatz:
DO
CR I . I EMIT SPACE SPACE
LOOP CR ;
80 64 .ASCII
256 32 do 16 0 do i j + dup . emit 2 spaces loop cr 16 +loop cr
Soll eine DO..LOOP vorzeitig und von einer Bedingung abhängend verlassen werden, benutzt man LEAVE
: TEST.LEAVE ( -- , demonstration von LEAVE )
100 0
DO
I . CR \ schleifenindex hinschreiben
I 20 > \ wenn I größer als 20 wird...
IF
LEAVE
THEN
LOOP ;
TEST.LEAVE \ gibt die zahlen 0 bis 20 aus
HINWEIS:
Das "traditionelle" LEAVE manipuliert nur die Schleifenparameter so, daß
LOOP dann keinen Rücksprung mehr durchführt. Damit wird nach einem
LEAVE immer noch der Rest bis zum LOOP durchlaufen. Um das zu vermeiden,
führt man bei Bedarf die umgebende Entscheidungsstruktur - ohne welche
LEAVE ohnehin nicht sinnvoll verwandt werden kann, mit einem ELSE-Teil bis vor
das LOOP.
Diese Variante liegt in L4 und F4 vor! nicht die ANS-4th-Form:
Obiges Beispiel veranschaulicht, daß LEAVE nur nach Auswertung einer
Bedingung sinnvoll einsetzbar ist. Die nach us-ANS erforderliche Eigenschaft
sofortigen Verlassens der Schleife ist überflüssig, kompliziert
aber den zugehörigen Compiler ganz enorm - es kann z.B. in der
werweißwievielten IF-Ebene stecken, und sein Compiler muß sich
dann durch alle Etagen "hocharbeiten". Da der innere Aufwand einer DO..LOOP
ohnehin recht hoch ist, hat das "traditionelle" Modell keinen nennenswerten
Laufzeit-Nachteil.
Zusätzlich stellen L4, F4 noch ein bedingtes -LEAVE bereit, das
ohne IF-Umgebung auskommt.
+LOOP benutzt man, wenn der Zählschritt andere, u.U. erst im Programmverlauf ermittelte Werte annehmen soll. Dies kann auch innerhalb der Schleife geschehen. Die Schrittweite wird als Parameter im Stack an +LOOP übergeben:
1025 1 DO I . I +LOOPschreibt z.B. die Zweierpotenzen von 1 bis 1024 hin.
Schließlich gibt es noch die Konstruktion aus
BEGIN ... (flag) WHILE ... REPEATDer Teil zwischen WHILE und REPEAT wird ausgeführt, wenn WHILE einen Wert =/= Null (TRUE) aufnimmt, bei FALSE wird dagegen die Schleife durch Sprung hinter das REPEAT verlassen.
ENTER BEGIN ..unbedingter teil.. ENTRY ..bedingter teil.. UNTILBeispiel in standardmäßiger Form
: SUM.OF.N ( N -- SUM[N] , summe der ersten N ganzzahlen )Dasselbe mit ENTER (L4, F4)
0 \ anfangswert
BEGIN
OVER 0> \ N größer Null?
WHILE
OVER + \ N zur summe addieren
SWAP 1- SWAP \ nächstes N
REPEAT
SWAP DROP ; \ N verwerfen
4 SUM.OF.N \ gibt 10 aus ( 1+2+3+4 )
: SUM.OF.N ( N -- SUM[N] , summe der ersten N ganzzahlen )Das ENTER/ENTRY-Paar ist leicht in "hi-level"-Code nachzubilden, ein system-spezifisches Beispiel liefert auch die "lib4th"-Sammlung.
0 \ anfangswert
ENTER BEGIN
OVER + \ N zur summe addieren
SWAP 1- SWAP \ nächstes N
ENTRY
OVER 0> 0= \ N nicht größer Null?
UNTIL
SWAP DROP ; \ N verwerfen
4 SUM.OF.N \ gibt 10 aus ( 1+2+3+4 )
Oben wurde der Umgang mit KEY und EMIT für einzelne Zeichen beschrieben, hier wollen wir uns mit größeren, geschlossenen Textstücken ("strings") befassen. Text kann mit Hilfe von S" in Worte eingebaut werden (L4, F4: auch im interpretierenden Zustand verwendbar). Das erste Leerzeichen danach gehört nicht zum Text, es ist die übliche Begrenzung des Forth-Wortes S". Abgeschlossen wird der Text durch ein Anführungszeichen ("), das ebenfalls selbst nicht zum Text gehört.
: TEST S" Huhu, da draußen!" ; ( -- p u )TEST hinterläßt zwei Posten im Stack, oben die Länge, dann den Pointer auf die Speicherstelle des ersten Zeichens im Text.
TEST .S
Mit den bekannten Worten kann er etwa so ausgegeben werden
TEST DROP \ zähler verwerfenCHAR+ zählt den Pointer um eine Zeichenposition weiter. Wobei solches Vorgehen irgendwann mit Unsinn (und "segfault") endet.
DUP C@ EMIT \ zeigt das erste zeichen an, "H"
CHAR+ DUP C@ EMIT \ das zweite, "u"
\ und so weiter ...
Einen ganzen String gibt TYPE aus.
TEST TYPE
TEST 2/ TYPE \ nur die hälfte...
S" erzeugt die nach derzeitigem Standard ("DPANS94") und durchaus vernünftig begründet favorisierte Variante. Es gibt aber auch die "althergebrachte" Form des "counted string", oft "Forth-String" genannt, bei dem man nur den Pointer (die Speicheradresse des String) zu übergeben braucht. ANS-Forth "FIND" erwartet etwa eine solche Angabe (soviel zur Konsistenz jenes "Standard"). Die Länge ermittelt daraus das Wort COUNT. Was den Vorteil hat, daß der innere Aufbau eines String nur diesem Wort bekannt sein muß und er dennoch mit den üblichen Forth-Worten bearbeitet werden kann. In L4 und F4 gibt es z.B. eine Variante von unbegrenzter Länge, die bei einem führenden <nul>-Byte angenommen wird, wo COUNT nach einer abschließenden <nul> sucht, statt "das" Count-Byte zu verwenden, das gemeinhin einen Forth-String anführt. Der klassische "counted string" ist die schnellere, aber wegen der Angabe in Bytegröße auf 255 Zeichen begrenzte Variante, da das Ende nicht erst abgezählt werden muß, wie in der mit <nul> abgeschlossenen, auch "asciz-string" oder "C-string" (weil in einer gewissen Programmierhilfe besonders favorisiert) benannten Form.
Ein Forth-String entsteht mit C"
: T2 C" Herzlichst, ich" ;Es wurde der Pointer auf den String ausgegeben.
T2 .
T2 20 DUMPzeigt, was an dieser Stelle gespeichert wurde.
T2 C@ .schreibt die Länge des Textes hin - sofern "das countbyte" wirklich ein Solches ist!
T2 COUNT TYPEschließlich gibt den Text aus.
TYPE nimmt den Wert für die Anzahl Zeichen vom Stack und ist in der Ausgabelänge im allgemeinen nicht begrenzt. Während der Ausgabe selbst ist mancher Rechner anderweitig kaum mehr steuerbar, darum wurde in L4 als Maßnahme gegen Irrläufer die Kappung auf max. 64K Bytes eingeführt.
CHAR+ ( ptr -- ptr' , ptr um ein zeichen weiterzählen )
COUNT ( ptr -- ptr' #bytes , ptr auf text und länge ermitteln )
TYPE ( ptr #bytes -- , #bytes text ab ptr ausgeben )
Die nächsten Beispiele können oft recht nützlich sein, sodaß es vielleicht sinnvoll ist, sie zum späteren Compilieren in eine Datei zu übernehmen.
Mit ACCEPT läßt sich sehr einfach ein String aus der Eingabe holen. Das Wort nimmt Zeichen aus der Tastatureingabe (oder auch von Files) auf und legt sie an einer angegebenen Stelle im Speicher ab. Die Anzahl empfangener Zeichen wird im Stack zurückgegeben.
ACCEPT ( ptr max -- len, text aus tastatur nach ptr )Das Eingabewort:
: INPUTS ( -- ptr )INPUTS erzeugt einen String aus der Tastatureingabe und gibt ihn zugleich als Echo im Bild aus. Hierbei stehen alle Editierfunktionen zur Verfügung, die das jeweilige ACCEPT eines Forth-Systems bietet.
PAD DUP 1+ ( ablageort, platz für countbyte )
128 ACCEPT ( maximal 128 zeichen aufnehmen )
OVER C! ( zähler einbauen, ptr auf PAD im stack )
;
INPUTS COUNT TYPE
INPUTS könnte etwa für einen Formbrief zur Adresseneingabe benutzt werden
: FORMBRIEF ( -- )
." Kundenname: " CR
INPUTS
CR ." Lieber " DUP COUNT TYPE CR
." Ihre Tasse mit der Aufschrift " COUNT TYPE
." ist in der Post!" CR ;
Mit INPUTS kann man ein Wort zur Zahleneingabe aufbauen
: INPUT# ( -- N true | false )INPUT# gibt eine einfach-genaue Zahl zurück und TRUE, oder nur FALSE.
INPUTS ( string holen )
NUMBER? ( zahl extrahieren )
IF DROP TRUE ( höherwertigen posten verwerfen )
ELSE FALSE
THEN ;
NUMBER? ist ein immer wieder gern zitiertes Wort, das jedoch weder im fig-Standard noch im ANS-4th existiert, ebensowenig in L4/F4 - wo [NUMBER] in etwa dasselbe erledigt. Es muß also ggf. erst noch definiert werden. Mit Standard-Worten und L4-verträglich:
DEFINED DPL \ "DEFINED" wie gehabt: auch DPL ist nicht "ANS-4th"wobei das einfacher, kürzer und vor allem vollständig möglich ist, wenn man durchaus übliche, aber im ANS-4th nicht angegebene Worte benutzt. Hier ist es ratsam, die jeweilige Dokumentation zu konsultieren, obige Definition ist nur ein Gerüst, mäßig brauchbar.
[IF] [ELSE] 0 VARIABLE DPL DPL ! [THEN]
BASE @ HEX \ für den "DPL"-Vergleich
: NUMBER? ( ptr count -- dn true | false )
DEPTH 4+ >R
COUNT 0. 0. 2ROT \ L4: einmal "0." reserve falls "quad" kommt
>NUMBER \ zahl extrahieren
DUP
IF 1 /STRING >NUMBER THEN \ falls "." o.dgl. im string
R> SWAP 0= >R \ flag aus stg-rest
DEPTH SWAP DO DROP LOOP \ nur double abliefern
DPL @ FFFF8F00 and 8000 - \ L4: 0 bei vierfachgenauer zahl
IF 2SWAP THEN 2DROP \ quad-hi oder reserve-0. verwerfen
R> ; \ flag zurück
BASE !
Das "neuzeitliche" Zählsystem ist dezimal, d.h. Zahlenbasis ist 10.
Was besagt, daß eine geschriebene Zahl 527 gleichbedeutend ist mit
( 5*100 + 2*10 + 7 ). Die 10 als Zahlenbasis
ist rein willkürlich festgelegt, ohne vernünftigen Grund, nur
Herleitung aus dem Unvermögen, größere Werte zu erfassen,
als die an den Fingern abzählbaren...
Im alten Babylon galt die Basis 60, bis vor garnichtmal so langer
Zeit in Deutschland auch, rsp. die 12 (Dutzend, Mandel, Schock, etc.),
übriggeblieben trotz krampfhafter Neuerungsversuche
sind die Gradeinteilung des Kreises und die Aufteilung von Stunden
in Minuten und Minuten in Sekunden. Nun gut. Im Computer haben wir
es in den elementaren Bereichen mit der Basis 2 zu tun, und gerechnet
wird zumeist sedezimal (Basis 16) oder oktal (Basis 8), neben dem
Dezimalsystem.
Was das dringende Verlangen erzeugt, in jederzeit und an jeder Stelle
beliebig wechselbarer Ziffernbasis rechnen zu können. Es geht.
Ganz ohne Problem. Forth beweist es, jedes Rechnersystem könnte
es, muß es doch stets ohnehin wenigstens von Binaer auf Dezimal
umrechnen, wenn es nur die betr. Berechnungsgrundlage zum Anwender rsp
Programmierer hin durchreichen würde. - Etwa die "bash" im Linux
bietet immerhin die Auswertung an, z.B. "echo $((16#123))", aber
auch dort ist die allgemeine Ziffernbasis selbst nicht änderbar.
DECIMAL 6 BINARY .oder was ist sedezimal 3E7 oktal? oder dezimal? Man mache selbst einmal den Versuch.
1 1 + .
1101 DECIMAL .
DECIMAL 12 HEX .Das große Geheimnis steckt allein in der (User-)Variablen BASE. Deren Inhalt bestimmt zum Zeitpunkt der Umrechnung die gerade anzuwendende Zahlenbasis. Nur sie muß ggf. nach Bedarf verändert werden, es entsteht keinerlei Nachteil für Laufzeit oder Speicherplatz - von der je nach gewählter Basis notwendigen, unterschiedlichen Ziffernanzahl abgesehen. So gut wie jeder irgendwie sinnvoll verwendbare Wert kann benutzt werden, im ANS-4th garantiert ist der Bereich 2 bis 36.
DECIMAL 12 256 * 7 16 * + 10 + .S
DUP BINARY .
HEX .
7 BASE !- nicht wundern, (nach)rechnen -
6 1 + .
BASE @ .
L4
erlaubt die bequeme Ein- und Ausgabe von Zahlen in den am häufigsten
interessierenden Basis-Werten, bei der Eingabe besonders einfach durch ein
der Zahl unmittelbar vorangestelltes Zeichen. Für die Ausgabe gibt es
u.a. die Worte $.
(sedezimal), #. (dezimal), &. (oktal) und %.
(binaer).
Direkt gesetzte Basis-Werte können im Bereich 2 bis 196 und - ohne jede
umwandlung - 256 verarbeitet werden, dazwischen entstehen Rechenfehler. Im
RATIONAL-Vocabular kann auch mit Fließkomma- und Bruchzahlen in
gleicher Weise zu beliebiger Basis gerechnet werden. Der Möglichkeiten
sind viele, man ziehe darum besser die ausführliche Dokumentation und
das HELP-Wort zurate. Insbes. das Wort A-BASE ist
aufschlußreich.
#14 BASE ! §123456 DUP $. DUP #. DUP &. DUP %. U. DECIMAL
Wie $. kann auch 0x als Praefix für sedezimale Zahlen
angegeben werden, für oktal mit & gilt auch @, nach
"OTA"-Standard.
Im F4 gelten dieselben Praefices für die Eingabe, zur
Ausgabe in beliebigem Ziffernsystem gibt es dort die Worte b. und db.,
die als erstes die Basis des gewünschten Ziffernsystems erwarten. Etwa mit
obigem Beispiel:
#14 BASE ! §123456 DUP #16 b. DUP #10 b. DUP 0 #8 db. DUP 0 #2 db. U. DECIMAL
Alle Forth-Worte werden in eine Liste eingereiht, wo sie der Interpreter nach entsprechender Eingabe heraussucht. Es kann mehrere davon geben, und dann spricht man von "Wortlisten" (nur ANS-4th) und "Vocabularen" (traditionell), in ihrer Gesamtheit dem "dictionary". Sie sind als "wordlist" durch Namen greifbar und als "vocabulary" in besonders einfacher Form aufzurufen, indem sie nach Hinschreiben des Namen die von da an vorrangig zu durchsuchende Wortliste festlegen. {WORDLIST} rsp. {VOCABULARY} sind Definitionsworte, mit denen jeweils eine entsprechende Liste eingerichtet wird. Ebenso wie andere Worte werden auch sie in das gerade gültige Definitions-Vocabular ("current") eingereiht, sodaß sich Wortgruppen hierarchisch voneinander abkapseln lassen ("name spaces"). Gewöhnlich werden Vocabulare "immediate" deklariert, der Wechsel vollzieht sich damit unmittelbar bei Antreffen des Namen auch innerhalb einer Wortdefinition während des Compilierens.
Fragen wir uns nach dem Nutzen dieser Einrichtung, so ergeben sich u.a. folgende Vorteile:
also \ alten "context" sichernÜbersetzen wir das Wort "also" mit "außerdem", wird dessen Funktion ohne weiteres klar. Mit "previous" stellt man ggf. den alten Zustand der Such-Ordnung wieder her. - Diese Spielerei mag einen gewissen Eindruck von den vielfältigen Möglichkeiten geben, die sich durch die Vokabulare eröffnen.
forth also definitions \ "forth" wird "context" und "current"
vocabulary zuhause immediate
vocabulary auf-arbeit immediate
zuhause definitions forth \ "zuhause" wird "current", "forth" bleibt "context"
: meier? ." bin arbeiten. " ;
auf-arbeit definitions forth
: meier? ." wer stoert? " ;
also forth \ zugänglichkeit des vocabulars sicherstellen
also auf-arbeit also zuhause
meier?
Mehr zu den Vokabularen soll hier nicht angegeben werden, dies war
bereits das Wesentliche. Übung allein hilft hier weiter, und
ein wenig Entschlußbereitschaft bei deren Einsatz.
Hinweis am Rande: Manche Forth-Systeme (nicht L4) haben Probleme mit FORGET,
wenn die zu löschende Aufrufkette durch mehrere Vocabulare geht. Oft
ist seine Wirkung allein auf den jeweils aktuellen "context" beschränkt
und auch nur dann verläßlich, wenn jener zwischendurch nicht
gewechselt wurde. Immer problematisch ist der Fall, wo auch das gerade "current"
oder "context" gesetzte Vokabular entfernt werden soll - L4 versucht
Wiederherstellung des vorherigen Zustands und stellt notfalls "forth" ein.
Genaueres ist der jeweiligen Dokumentation zu entnehmen.
Usancen, an die zu halten sich im allgemeinen empfiehlt, die aber nicht in irgendwelchen Standards verbindlich
gemacht wurden. Wo die Zweckmäßigkeit Abweichungen nahelegt, sollte den hier notierten Richtlinien
keine übergeordnete Bedeutung beigemessen werden.
Allgemein:
Ein paar grundlegende Kriterien, ohne deren Erfüllung ein Forth-System gewöhnlich wertlos ist, sind etwa
Lösungen zu den Aufgaben
Wenn die eigene Lösung Resultate liefert, die in Umkehr einer Probe standhalten, ist sie (im allgemeinen) auch richtig; es gibt meist viele Wege, eine bestimmtes Ergebnis zu erzielen. Darum bewerte man die folgenden Aufgabenlösungen als Hilfestellung oder Vergleichsinstrument, wo es weniger erheblich ist, ob der eigene, durch Probe bestätigte Weg davon abweicht.
Stack-Manipulation
1) SWAP DUP
2) ROT DROP
3) ROT DUP 3 PICK
4) SWAP OVER 3 PICK
5) -ROT 2DUP
Arithmetik
(12 * (20 - 17)) ==> 20 17 - 12 * (1 - (4 * (-18) / 6)) ==> 1 4 -18 * 6 / - (6 * 13) - (4 * 2 * 7) ==> 6 13 * 4 2 * 7 * - : SQUARE ( N -- N*N )
DUP * ;
: DIFF.SQUARES ( A B -- A*A-B*B )
SWAP SQUARE SWAP SQUARE - ;
: AVERAGE4 ( A B C D -- [A+B+C+D]/4 )
+ + + ( zusammenfassen )
2 rshift ( schnelle vorzeichenlose division durch vier )
;: HMS>SECONDS ( STD MIN SEC -- SEC' )
-ROT SWAP ( -- sec min h )
60 * + ( -- sec min.gesamt )
60 * + ( -- sec )
Logik-Operatoren
: LOWERCASE? ( CHAR -- FLAG , true bei kleinbuchstaben )
DUP 123 <
SWAP 96 > AND
;Entscheidungen
: DEDUCT ( n -- , kontostand vermindern )
KONTO @ ( -- n acc )
SWAP - DUP KONTO ! ( -- acc' , variable aktualisieren )
." Saldo = EUR " DUP . CR ( -- acc' )
0<
IF ." Konto überzogen!" CR
THEN
;
Schleifen
: SUM.OF.N.1 ( N -- SUM[N] )
0 SWAP \ anfangswert SUM
1+ 0 \ indices für DO LOOP
?DO \ sicherheitshalber, falls N=0
I +
LOOP
;
: SUM.OF.N.2 ( N -- SUM[N] )
0 \ anfangswert SUM
BEGIN ( -- N' SUM )
OVER +
SWAP 1- SWAP
OVER 0<
UNTIL
SWAP DROP
;: SUM.OF.N.3 ( NUM -- SUM[N] , Gauss'sche methode )
DUP 1+ \ SUM(N) = N*(N+1)/2
* 2/
;
Ersatzdefinitionen
S. anstelle .S mit Ausgabe in umgekehrter Reihenfolge
: S. ( -- )Dieses neue Wort kann dann wie für .S beschrieben die Bereitschaftsmeldung ersetzen.
0 depth 2- dup 1+
." D[" 0 .r ." :" base@ dup decimal 0 .r base! ." ] "
?do i pick u. -1 +loop ;Nachbildung von ROT
: ROT>R räumt einen Stackposten aus dem Wege. Es darf jedoch nur paarweise mit R> benutzt werden, nicht mit bedingten Programmteilen verschachtelt, und stets innerhalb eines und nur desselben (neuen) Wortes. Um es auf die Spitze zu treiben, auch ROLL ließe sich in dieser Weise nachbilden, oder man hat vielleicht ein sehr effizient eingerichtetes ROLL, dann wären
>R SWAP R> SWAP ;
: SWAP 1 ROLL ;Und von wegen "es darf...":
: ROT 2 ROLL ;
R> zusammen mit DROP wird gelegentlich bei Systemen, deren innerer Aufbau das erlaubt, auch zum vorzeitigen Rücksprung in die nächst höhere Aufrufebene benutzt.Auch das nicht überall angegebene -ROT ist leicht darstellbar:
: -ROT
ROT ROT ;
Nachbildung von MIN und MAX, vorzeichenbehaftet:
: MIN ( n1 n2 -- n )
OVER OVER > IF SWAP THEN DROP ;
: MAX ( n1 n2 -- n )
OVER OVER < IF SWAP THEN DROP ;
NEGATE zeigt, wie die Darstellung negativer Zahlen im Zweiercomplement definiert ist
: NEGATE ( n1 -- n )NOT ist die bitweise Umkehr eines Datenwertes:
NOT 1+ ;
: NOT ( n1 -- n )ABS negiert eine negativ bewertete Zahl:
-1 XOR ;
: ABS ( n1 -- n )
DUP 0 < IF NEGATE THEN ;
Elementare doppeltgenaue Operatoren:
: 2DUP ( a b -- a b a b , datenpaar DUPlizieren )
OVER OVER ;: 2DROP ( a b -- , die beiden oberen posten entfernen )
DROP DROP ;: 2SWAP ( a b c d -- c d a b , doppelten posten tauschen )
ROT >R ROT R> SWAP ;: 2OVER ( a b c d -- a b c d a b , OVER eines doppelten posten )
>R >R 2DUP R> R> 2SWAP ;: 2ROT ( a b c d e f -- c d e f a b , ROT doppelte posten )
>R >R 2SWAP R> R> 2SWAP ;SP> existiert im fig-Forth als {SP!} und wird, evtl. anders benannt, in vielen Forth-Varianten angeboten, auch in L4. Es dient dem Leeren des Datenstacks. Einfacher Ersatz ist leicht geschaffen
: SP> ( -- ){ 0 DEPTH ... } sorgt dafür, daß wenigstens ein Posten im Stack vorhanden ist und trägt so der Tatsache rechnung, daß DO...LOOP immer wenigstens einen Durchgang ausführt. Mit dem im ANS-Forth gegebenen {?DO} kann man stattdessen schreiben:
0 DEPTH 0 DO DROP LOOP ;: SP> ( -- )Je nach internem Aufwand wird allerdings die erste Variante meist schneller sein und oft auch kürzeren Code erzeugen. - So könnte das ?DO etwa durch Einbau der DO..LOOP in eine IF/ELSE-Abfrage dargestellt worden sein:
DEPTH 0 ?DO DROP LOOP ;.. 2DUP = IF 2DROP ELSE do ... loop THEN ..INCLUDE und INCLUDE? zur vereinfachten Namensangabe beim Laden von Files (in L4 vorhanden, {lload?} u.dgl bei F4):
: INCLUDE ( <leerzeichen>name -- )
BL WORD COUNT INCLUDED ;
schon für sich alleine zum bedingten Compilieren sehr nützlich ist
: DEFINED ( <leerzeichen>name -- flag )
BL WORD FIND SWAP DROP ;
damit INCLUDE?
: INCLUDE? ( <leerzeichen>name -- )
DEFINED IF POSTPONE \ ELSE INCLUDE THEN ;
Allein mit obigem DEFINED geht es im ANS-Forth auch:
DEFINED wortname 0= [IF] s" filename" INCLUDED [THEN]
<BUILDS zum Wortaufbau im fig-Forth:
: <BUILDS ( ccc, -- )
0 CONSTANT ;
DOES> ist in hi-level-Forth nicht darstellbar:: DOES> (C: -- ) (X: -- a ) \ DOES>-Variante des fig-ForthAuf obiges (;CODE) folgt in ausführbarem Processor-Code eine Kombination aus docolon und dovariable zum Einsprung in den DOES>-Teil mit Übergabe des in der PFA abgelegten Pointers.
R> LATEST PFA ! (;CODE) ( ... )
: (;CODE) ( -- ) \ Umbau der jüngsten Definition auf Einsprung in unmittelbar folgenden CPU-Code
R> LATEST PFA CFA ! ;
>BODY ist im fig-Forth einfach nur {4+}, da ' ('tick') die PFA liefert, wo bei Worten aus <BUILDS und DOES> die Adresse des Vorspanns zum Einsprung in den DOES>-Teil steht. Die compilierten Daten folgen unmittelbar darnach. - Dieses Schema ist im F4 wegen der Aufteilung in änderbaren und geschützten Speicher nicht ohne weiteres anwendbar.MARKER
ist so, wie üblicherweise definiert, nicht unbedingt trivial. Es läßt sich aber ganz leicht Ersatz schaffen, indem man am Anfang einer zu markierenden Codesequenz einfach FORGET eines leeren Wortes aufruft, das unmittelbar danach - ggf. erneut - definiert wird:FORGET marke : marke ;Da FORGET mitunter so eingerichtet ist, daß es mit Fehlermeldung abbricht, wenn das betr. Wort schon vorher nicht existiert, muß man es hier ggf. vom Vorhandensein der 'marke' abhängig machen. Dazu hilfsweise:
: IF-DEFINED DEFINED IF POSTPONE \ THEN ; ( ANS-4th, DEFINED s.o. )oder
: IF-DEFINED -FIND IF 2DROP [COMPILE] \ ENDIF ; ( fig-4th, auch THEN für ENDIF )und damit der 'MARKER'-Ersatz:
IF-DEFINED marke FORGET marke
: marke ;
12345 CONSTANT #ENTER \ kontrollzahl für den compilerFür ENTRY wird hier vorausgesetzt, daß BEGIN u.dgl. zwei Posten an Kontrolldaten im Datenstack hinterlassen, darum "2SWAP", was ggf. den Eigenheiten des jeweiligen Forth anzupassen ist. Im ANS-4th gibt es für solche Fälle CS-ROLL, hier { 1 CS-ROLL } anstelle des "2SWAP".
: ENTER ( -- ) ( C: -- a n )
COMPILE BRANCH HERE 0 , #ENTER ; IMMEDIATE
: ENTRY ( -- ) ( C: a n -- | abort, "abort" wenn n =/= #ENTER )
2SWAP #ENTER - IF ." conditionals not paired " QUIT THEN HERE OVER - SWAP ! ; IMMEDIATE
Forth Mini-Worts(ch)atz
Weder allgemeingültig noch einzigartig noch vollständig, eine Art Grundwortschatz der wichtigsten Forth-Worte. Angegeben sind nur die jeweiligen Grundformen ohne mehrfach-genaue Operationen, d.h. solchen, die mit Posten zu jeweils mehr als einer 'Zelle' arbeiten - welche sich mit wenigen Ausnahmen, z.B. M+, aus den Standardworten aufbauen lassen, s. 'Ersatzdefinitionen'. Der vollständige Wortsatz des fig-Forth ist im Glossar zum F4 erklärt, die Worte des ANS-4TH beschreibt das (englischsprachige) Glossar zur lib4th (L4).
Notierung wie in o.g. Stackdiagrammen:
Eine 'Zelle' hat die systemspezifische Standardgröße, 32 Bits bei lib4th und F4; ein 'Byte' hat dort 8 Bits und ein 'Character' (Schriftzeichen-Code) entspricht einem Byte. 'Zelle', 'Byte' u.dgl. sind Maße, nicht 'Datentypen'. Der Konflikt durch implizite Gleichsetzung von 'Byte' und 'Character' ist in den bisherigen Standards nicht gelöst - man könnte etwa 'B@' und 'B!' für die Byte-Größe des betr. Rechners vorsehen, 'C@' und 'C!' sind im Forth-Kern derart oft und mit festgelegter Identität 'Byte' = 'Character' vorhanden, daß sich Änderungen daran für ein standardnahes Forthsystem verbieten.
- ( -- ) Vorgänge im Datenstack ('D-Stack')
- ( C: -- ) D-Stack während des Compilierens, STATE =/= 0
- ( R: -- ) Vorgänge im Return-Stack
- ( X: -- ) D-Stack bei Ausführung einer angegebenen Wortdefinition
- a steht für eine Speicheradresse
- ccc das nächste durch Leerzeichen begrenzte Textstück im Eingabestrom
- f Flag, 'ff', 'false' = 0 und fig: 'tf', 'true' = 1, ans: 'tf', 'true' = -1
- n als vorzeichenbehaftete Zahl interpretierter Datenposten in Standardgröße
- u vorzeichenlos bewerteter Posten, etwa Länge einer Folge von Schriftzeichen
- c Datenposten in Größe eines Schriftzeichens ('character', i.a. ein Byte zu 8 Bits);
in den Stacks ist dies der entsprechende, niederwertige Anteil eines Posten in Standardgröße.- x beliebiger Datenposten
Arithmetik + ( n1 n2 -- n ) Addition. - ( n1 n2 -- n ) Subtraktion. * ( n1 n2 -- n ) Multiplikation. / ( n1 n2 -- n ) Division. /MOD ( n1 n2 -- n3 n ) Division mit Rest(n3). MOD ( n1 n2 -- n3 ) Divisionsrest. MAX ( n1 n2 -- n ) die vorzeichenbehaftet größere zweier Zahlen im D-Stack belassen. MIN ( n1 n2 -- n ) die vorzeichenbehaftet kleinere zweier Zahlen im D-Stack belassen. M+ ( d1 n2 -- d3 ) einfache zu doppeltgenauer Ganzzahl vorzeichenbehaftet addieren ABS ( n -- n' ) Negation, wenn n < 0 MINUS ( n -- n' ) fig: Negation des Wertes n NEGATE ( n -- n' ) ans: Negation des Wertes n +- ( n n1 -- n' ) Vorzeichen n1 auf Wert n anwenden, n' := n * signum(n1)
Logik< ( n1 n2 -- f ) 'tf', wenn n1 vorzeichenbehaftet kleiner als n2 ist. U< ( u1 u2 -- f ) 'tf', wenn u1 vorzeichenlos kleiner als u2 ist. = ( n1 n2 -- f ) 'tf', wenn n2 denselben Wert hat, wie n1. 0= ( n1 -- f ) 'tf', wenn n1 Null ist. 0< ( n1 -- f ) 'tf', wenn n1 kleiner Null ist. NOT ( u1 -- n ) fig: bitweise Umkehr des Wertes u1. INVERT ( u1 -- n ) ans: bitweise Umkehr des Wertes u1. AND ( u1 u2 -- u ) bitweise UND-Verknüpfung OR ( u1 u2 -- u ) bitweise ODER-Verknüpfung XOR ( u1 u2 -- u ) bitweise ANTIVALENZ-Verknüpfung;
Bit in n gesetzt wenn die entspr. Bits in n1 und n2 ungleich sind. Stacks DUP ( x -- x x ) erste Zelle des D-Stack duplizieren -DUP ( x -- x x | 0 ) fig: falls =/= 0, erste Zelle des D-Stack duplizieren ?DUP ( x -- x x | 0 ) ans: falls =/= 0, erste Zelle des D-Stack duplizieren DROP ( x -- ) erste Zelle des D-Stack verwerfen SWAP ( x1 x2 -- x2 x1 ) die beiden oberen Zellen im D-Stack vertauschen OVER ( x1 x2 -- x1 x2 x1 ) zweiten Stackposten nach 'oben' copieren. ROT ( x1 x2 x3 -- x2 x3 x1 ) dritten Posten im Datenstack nach 'oben' holen, die beiden bis dahin oberen eine Position nach 'unten' copieren. >R ( x -- ) (R: -- x ) Zelle vom D-Stack zum Return-Stack verlagern R ( -- x ) (R: x -- x ) 'oberen' Posten von Return-Stack zum D-Stack copieren. R> ( -- x ) (R: x -- ) Zelle vom Return-Stack zum D-Stack verlagern.
Speicher@ ( a -- x ) Zelle x von Addresse a zum D-Stack C@ ( a -- c ) Zeichencode c von Adresse a zum D-Stack
üblicherweise wird c mit einem 8-Bit-Byte gleichgesetzt, desgl. bei {C!} ! ( u a -- ) Zelle n an Adresse a speichern C! ( c a -- ) Zeichencode c an Adresse a speichern HERE ( -- a ) Inhalt der Variablen 'DP', Anfang des freien 'dictioinary'-Speichers. PAD ( -- a ) min. 80 Bytes Hilfsspeicher in festem Abstand jenseits 'HERE'. BLANKS ( a u -- ) Anzahl u Bytes '<bl>' (Code 32) ab Speicheradresse a eintragen. ERASE ( a u -- ) Anzahl u Bytes ab Speicheradresse a löschen (Null setzen). FILL ( a u c -- ) Anzahl u Bytes c ab Adresse a speichern. CMOVE ( a1 a2 u -- ) Anzahl u Bytes von a1 nach a2 zu höheren Adressen hin übertragen. <CMOVE ( a1 a2 u -- ) Anzahl u Bytes von a1 nach a2 von höheren Adressen her übertragen.
Ein- und AusgabeEMIT ( n -- ) Zeichencode n zur Standard-Ausgabe. TYPE ( a u -- ) Anzahl u Schriftzeichen ab Adresse a zur Standard-Ausgabe CR ( -- ) Vorschub zum nächsten Zeilenanfang zur Standard-Ausgabe. SPACE ( -- ) ein Leerzeichen zur Standard-Ausgabe. SPACES ( n -- ) Anzahl +n Leerzeichen zur Standard-Ausgabe. KEY ( -- c ) Zeichen von der Standard-Eingabe aufnehmen; Verfügbarkeit abwarten. ?KEY ( -- c 1 | 0 ) Zeichen aus Standard-Eingabe aufnehmen und mit 'tf' zurückgeben; nur 'false' abliefern, wenn keine Eingabe verfügbar; nicht warten. KEY? ( -- f ) ans: 'tf', wenn Eingabe verfügbar, sonst 'false'; nicht warten. ?TERMINAL ( -- f ) fig: 'tf', wenn Eingabe verfügbar, sonst 'false'; nicht warten. ACCEPT ( a u -- u1 ) ans: max Anzahl u Zeichen aus der Eingabe nach Adresse a holen; vorzeitiger Abbruch bei (codiertem!) Eingabe- oder Zeilenende; Anzahl empfangener Zeichen wird mit u1 zurückgegeben. Wenn stdin ein Terminal beschreibt, kann der Text editiert werden. EXPECT ( a u -- ) fig: Anzahl empfangener Zeichen in der Variablen SPAN, sonst wie ACCEPT
ZahlenBASE ( -- a ) Variable, Basis des gerade geltenden Ziffernsystems DECIMAL ( -- ) Dezimale Zahlenbasis einstellen, s. 'BASE' HEX ( -- ) Sedezimale Zahlenbasis einstellen, s. 'BASE' <# ( -- ) Umwandlung eines Zahlenwertes zum Textstrang vorbereiten #> ( d -- a u ) Umwandlung eines Zahlenwertes zum Textstrang abschließen: oberen doppelten Posten von D-Stack entfernen; Speicheradresse und Anzahl Textzeichen dort ablegen. # ( d -- d1 ) niedrigstwertige Ziffer der Zahl d extrahieren und dem mit '<#' vorbereiteten Text voranstellen. #S ( d -- 0. ) solange '#' ausführen, bis nur noch Null übrigbleibt HOLD ( c -- ) Zeichencode c dem vorbereiteten Text zur Zahlenausgabe voranstellen (NUMBER) ( d a -- d1 a1 ) Text ab Adresse a+1 als Zahl interpretiert zum Wert d accumulieren;
Abbruch ohne Fehler beim ersten nicht als Ziffer auswertbaren Zeichen. NUMBER ( a -- d | abort ) Text ab Adresse a+1 als Zahl interpretieren, ABORT bei Fehler. .R ( n n1 -- ) Zahl n rechtsbündig in einem Feld von Anzahl +n1 Leerzeichen ausgeben. . ( n -- ) Zahl n mit einem folgenden Leerzeichen zur Standard-Ausgabe. ? ( a -- ) Speicherzelle a als Zahl mit einem folgenden Leerzeichen ausgeben.
Interpreter u.a.DEFINITIONS ( -- ) CONTEXT-Vocabular zum Definitionsvocabular machen. -FIND ( ccc, -- pfa byte 1 | 0 ) fig: Wort ccc suchen; pfa, Flag-/Count-Byte, 'true' Flag zurückgeben;
nur Null, wenn der Name ccc nicht gefunden wurde. FIND ( a -- pfa 1 | pfa -1 | a 0 ) ans: Wort ccc suchen; pfa und -1 zurückgeben, +1 für 'immediate';
'ff', wenn der Name aus dem Forth-String bei a nicht gefunden wurde. WORDS ( -- ) ans: Alle Worte des CONTEXT-Vocabulars anzeigen. VLIST ( -- ) fig: Alle Worte des CONTEXT-Vocabulars anzeigen. ID. ( nfa -- ) zur übergebenen nfa gehörigen Wortnamen in Standard-Ausgabe senden. CFA ( pfa -- cfa ) aus pfa die zugehörige cfa ('code field address') ermitteln. NFA ( pfa -- nfa ) aus angegebener pfa die zugehörige nfa ermitteln (s. PFA). PFA ( nfa -- pfa ) aus nfa ('name field address') die zugehörige pfa ('parameter field address') ermitteln. QUERY ( -- ) fig: bis zu 80 Zeichen aus der Eingabe holen und interpretieren. QUIT ( -- ) der 'Äußere Interpreter' des Forth ( ( ccc, -- ) Text bis zur nächsten schließenden Klammer ")" unbeachtet lassen. WORD ( c -- a ) ans: nächsten durch Zeichen c eingeschlossenen Text aus dem Eingabestrom nach Adr. a holen. WORD ( c -- ) fig: nächsten durch Zeichen c eingeschlossenen Text aus dem Eingabestrom nach 'HERE' holen.
Programmablauf, compilierende, 'immediate' Worte.IF ( f -- ) leitet bedingt bei 'true' auszuführenden Programmteil ein
( flag ) ... IF ... ELSE ... ENDIF ... ', 'ELSE'-Teil kann entfallen. ELSE ( -- ) leitet alternativ nach 'IF' auszuführenden Programmteil ein ENDIF ( -- ) schließt durch 'IF' eingeleitete Programmteile ab, ggf nach 'ELSE'. THEN ( -- ) wie ENDIF (jüngere fig-4th-Varianten, ANS-4th). BEGIN ( -- ) leitet bedingt abzubrechende Schleife ein; Varianten:
' .. BEGIN ... . ... AGAIN ' endlos durchlaufene Schleife ' .. BEGIN .. ( n ) WHILE .. REPEAT .. ' Abbruch nach n = 0 vor 'WHILE' ' .. BEGIN .. .. ( n ) UNTIL .. ' Abbruch nach n =/= 0 vor 'UNTIL' AGAIN ( -- ) unbedingte Rückkehr zum Schleifeneinsprung nach 'BEGIN'. REPEAT ( -- ) unbedingte Rückkehr zum Schleifeneinsprung nach 'BEGIN'. UNTIL ( f -- ) durch f = 0 bedingte Rückkehr zum Schleifeneinsprung nach 'BEGIN'. WHILE ( f -- ) bei f = 0 verlassen einer 'BEGIN'-Schleife hinter deren 'REPEAT'. DO ( n1 n2 -- ) leitet eine Schleife ein, die bei Überlauf des am Ende jeden Durchgangs weitergezählten Schleifenindex in oder über die Obergrenze n1 hinaus aus Richtung vom Startwert n2 verlassen wird. Innerhalb der Schleife steht mit 'I' der Laufindex zur Verfügung.
' ( grenze anfang ) .. DO .. I .. LEAVE .. LOOP ' ' ( grenze anfang ) .. DO .. I .. LEAVE .. ( schrittweite ) +LOOP ' I ( -- n ) der je Durchgang eins weitergezählte Laufindex der umgebenden DO..LOOP. LEAVE ( -- ) Irreguläres Verlassen einer DO..LOOP/+LOOP am Schleifenende. +LOOP ( n -- ) Ende einer DO..+LOOP mit Weiterzählen des Laufindex um den Wert n. LOOP ( -- ) Ende einer DO..LOOP.
CompilerALLOT ( n -- ) Reservierung von +n Bytes im 'Dictionary' ab 'HERE', Rücknahme einer Reservierung bei n<0. , ( n -- ) Speicher-Reservierung und Ablage des Wertes n in der Zelle bei 'HERE'. C, ( n -- ) gesicherte Ablage von n im Format eines Schriftzeichen-Code bei 'HERE'.
Die übliche Verwendung zur Ablage eines 8-bit Byte führt u.U. zum
Konflikt zwischen 'byte' und wirklicher Anzahl Bits per Schriftzeichen,
denn ein 'byte' muß weder identisch 'character' sein, noch 8 bits groß! LITERAL ( n -- ) Datenposten n als Zahl in ein Wort compilieren. CONSTANT ( ccc, n -- ) (X: -- n ) Constante mit Namen ccc und Wert n einrichten. VARIABLE ( ccc, -- ) (X: -- a ) ans: Variable mit Namen ccc einrichten, Wert nicht initialisiert VARIABLE ( ccc, n -- ) (X: -- a ) fig: Variable mit Namen ccc und Wert n einrichten. : ( ccc, -- ) Beginn der Definition eines Forth-Wortes mit dem Namen ccc. ; ( -- ) Definition eines Wortes beenden und es namentlich aufrufbar machen. CREATE ( ccc, -- ) Legt einen Wort-header an:
fig: baut 'primitive'-header als Einsprung in Forth-Routine auf;
das Wort ist noch unvollständig und für -FIND nicht 'sichtbar'.
ans: Namentlich identifizierbare Speicheradresse (ohne Zuweisung),
kann für FIND freigegeben und wie eine Variable aufgerufen werden.
<BUILDS ( ccc, -- ) nur fig: Anlegen eines Wortheaders durch ein Definitionswort,
es folgt der Initialierungscode für damit erzeugte Worte;
DOES> ( -- ) (X: -- a ) Einleiten der Ausführungsvorschrift innerhalb eines Definitionswortes;
liefert beim Aufruf eines damit erzeugten Wortes dessen pfa zum dstack,
diese zeigt auf den dem betr. Wortheader unmittelbar folgenden Datenbereich.
IMMEDIATE ( -- ) jüngste Wortdefinition zur sofortigen, von STATE unabhängigen Ausführung modifizieren. SMUDGE ( -- ) fig: 'Sichtbarkeit' der jüngsten Wortdefinition für -FIND umschalten. LATEST ( -- a ) nfa der jüngsten Wortdefinition im 'CURRENT'-Vocabular [ ( -- ) Compilierenden Zustand suspendieren. ] ( -- ) Compilierenden Zustand einstellen.
Variable, ConstanteBL ( -- c ) Constante, Zeichencode für das Leerzeichen (32). BASE ( -- a ) Variable, Basis des gerade geltenden Ziffernsystems CELL ( -- u ) Constante, Anzahl Bytes einer 'Zelle', systemspezifisch. CONTEXT ( -- a ) Variable, a zeigt auf das Vocabular, bei dem -FIND die Wortsuche beginnt CURRENT ( -- a ) Variable, a zeigt auf das Vocabular, dem neue Worte zugeordnet werden DP ( -- a ) Variable, 'dictionary pointer', der Ort im Speicher, an dem zunächst compiliert wird. SPAN ( -- a ) Variable, Anzahl der von EXPECT (und damit auch QUERY) empfangenen Zeichen. LAST ( -- a ) nfa der insgesamt jüngsten Wortdefinition (nicht 'LATEST'!) STATE ( -- a ) Variable, System im compilierenden Zustand wenn =/= Null.
Block-FilesB/BUF ( -- u ) Constante, nutzbare Anzahl Bytes per Block-Puffer. B/SCR ( -- u ) Constante, Anzahl Block-Puffer per 'Screen'. C/L ( -- u ) Constante, Zeichenanzahl je Zeile einer 'Screen' (konventionell 64). C/SCR ( -- u ) Zeichenanzahl einer 'Screen', konventionell 1024, "C/SCR" ist nicht Standard! BLK ( -- a ) Variable, hält die Nummer des gerade gepufferten Screenfile-Blocks. PREV ( -- a ) Variable, Adresse des gerade benutzten Blockpuffers. SCR ( -- a ) Variable, Nummer der jüngst mit LIST angzeigten 'Screen'. FIRST ( -- a ) Untergrenze des Speichers für Block-Puffer. LIMIT ( -- a ) Obergrenze des Speichers für Block-Puffer. BLOCK ( n -- a ) holt den Screenfile-Block Nr. n in den Speicher an Adresse a. BUFFER ( n -- a ) reserviert Pufferspeicher für den Screenfile-Block Nr. n an Adresse a. +BUF ( a -- a1 f ) Adresse des nächsten Blockpuffers ermitteln, f=0 wenn PREV @ = a1. EMPTY-BUFFERS ( -- ) alle verfügbaren Pufferspeicher mit <nul>-Bytes löschen. LOAD ( n -- ) Eingabe ab 'screen' n vom aktuellen Blockfile-Medium holen. ;S ( -- ) zum (vorzeitigen) Abbruch des compilierens einer Blockfile-Quelle. (LINE) ( n1 n2 -- a ) holt Zeile n1 der Seite ('screen') n2 in den Speicher an Adresse a LIST ( n -- ) übergibt n in die Variable 'SCR' und zeigt diese 'screen' an. R/W ( a n f -- ) f=1: Block Nr. n vom Datenträger holen und an Puffer-Adresse a ablegen, f=0: an Adresse a gepufferten Block Nr. n zum Datenträger schreiben.
: